いい感じに自然言語でサイト内の記事を検索する機能を作ってみたかったので、2つサイトに追加した
コンセプトとしては検索エンジン的なサーバーをなるべく持たない形で関連ページを取得するもの。また、あくまで記事を読みに行くのを促す機能としたいので、検索結果に表示するのも概要の要約までにとどめている
ai agentによる記事検索
こちらの記事 https://blog.uni-3.app/a2a-local-search-agent/
で作ったai agentを用いた検索機能を実際に動かした感じ
実際には、sequential agentにして、responseを特定のjsonオブジェクトで返すようにしているが、基本(agentの構成、処理順序など)は変えていない
- システム構成

ai agentが動作するserverはgoogle cloud runに設置して、リクエスト後agentのメッセージをやり取りするclientはastro apiとした
mcp serverからはjsonで返して、clientなどで表示をいじりたかったので構造化するagentとして実装した。このばあいはsequential agentという、タスクの実行順序を決められたagentとして作る必要があるらしい
- 画面
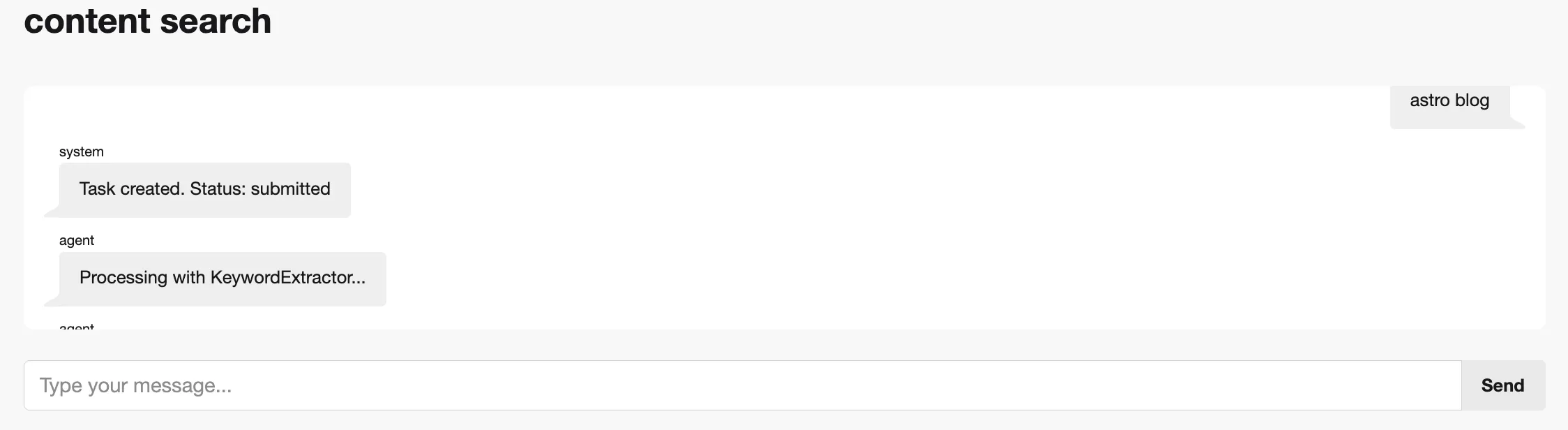
あまり意味はないが、処理中、動いているエージェントをstreamで返すようにしてみている

チャットっぽい見た目にしたのはなんとなく。検索エンジンから関連記事を取得してdescriptionもしくは、要約した文章を返す
ページは以下。トップページにあってもな、となったので、アーカイブページにリンクを適当に設置している
https://blog.uni-3.app/content-search-agent/
実装
a2a client部分のみおいておく
- a2a client(astro api)
agentの返り値のパース部分など、だいぶ試行錯誤したままのコードだけど、きにしない
server側はstream形式で処理中のタスクを返すようにしてみてるのでが、clientでもstreaming処理する。処理(一連のagentのタスク)が終わったら終わり。続けてセッションを使った検索はしない
export const prerender = false;
import type { APIRoute } from 'astro';
import { A2AClient } from '@a2a-js/sdk/client';
import type { Message, MessageSendParams, Task, TaskStatusUpdateEvent, TaskArtifactUpdateEvent, DataPart, TextPart} from "@a2a-js/sdk";
import { v4 as uuidv4 } from "uuid";
// component側に返すメッセージ形式
export type ChatMessage = {
id: string;
role: "user" | "agent" | "system";
content: string;
type: "message" | "status" | "error";
};
const sessions = new Map<string, Message[]>();
export const POST: APIRoute = async (context) => {
try {
const body = await context.request.json();
const { sessionId, query } = body;
if (!sessionId || !query) {
return new Response(JSON.stringify({ error: 'sessionId and query are required' }), { status: 400 });
}
if (!sessions.has(sessionId)) {
sessions.set(sessionId, []);
}
const sessionHistory = sessions.get(sessionId)!;
const newUserMessage: Message = {
kind: 'message',
messageId: uuidv4(),
role: 'user',
parts: [{ kind: 'text', text: query }],
};
sessionHistory.push(newUserMessage);
// Use Cloudflare runtime env vars if available (in production), otherwise fallback to Vite's env vars (for local dev).
const mcpServerUrl: string = context.locals.runtime?.env.MCP_SERVER_URL || import.meta.env.MCP_SERVER_URL;
if (!mcpServerUrl || !mcpApiKey) {
return new Response(JSON.stringify({ error: 'Server required environment variables are not set' }), { status: 500 });
}
const customFetch = (url: RequestInfo | URL, options?: RequestInit): Promise<Response> => {
const headers = new Headers(options?.headers);
return fetch(url, {
...options,
headers,
});
};
const client = await A2AClient.fromCardUrl(mcpServerUrl + "/.well-known/agent.json", {
fetchImpl: customFetch,
});
const params: MessageSendParams = {
message: {
...newUserMessage,
},
configuration: {
acceptedOutputModes: ["text/plain"],
},
};
const a2aStream = client.sendMessageStream(params);
const responseStream = new ReadableStream({
async start(controller) {
try {
for await (const event of a2aStream) {
let chatEvent: ChatMessage | null = null;
let agentMessageForHistory: Message | null = null;
// taskの状態に応じてpartをから中身取得
if ((event as Task).kind === "task") {
const task = event as Task;
chatEvent = { id: task.id, role: "system", content: `Task created. Status: ${task.status.state}`, type: "status" };
} else if ((event as TaskStatusUpdateEvent).kind === "status-update") {
const statusEvent = event as TaskStatusUpdateEvent;
const textParts = (statusEvent.status.message?.parts || []).filter((p): p is TextPart => p.kind === 'text');
const textContent = textParts.map(p => p.text).join('\n');
// 結果ありの場合はai agentからarticleのオブジェクト形式で返ってくる
type article = {
url: string | null;
title: string | null;
description: string | null;
}
if (statusEvent.final === true) {
const dataParts = (statusEvent.status.message?.parts || []).filter((p): p is DataPart => p.kind === 'data');
if (dataParts.length > 0 && dataParts[0].data && 'articles' in (dataParts[0].data as any)) {
const articles = (dataParts[0].data as any).articles as article[];
const text = articles.map((a, i) => `${i + 1}. **${a.title}**
- url: ${a.url}
- description: ${a.description}`).join('\n\n');
let res = text;
if (!res) {
res = "articles not found"
}
chatEvent = { id: statusEvent.status.message?.messageId || uuidv4(), role: "agent", content: res, type: "message" };
agentMessageForHistory = { kind: 'message', role: 'agent', messageId: chatEvent.id, parts: [{kind: 'text', text: res}] };
}
} else if (textContent) {
chatEvent = { id: statusEvent.status.message?.messageId || uuidv4(), role: "agent", content: textContent, type: "message" };
agentMessageForHistory = { kind: 'message', role: 'agent', messageId: chatEvent.id, parts: [{kind: 'text', text: textContent}] };
}
} else if ((event as Message).kind === "message") {
const messageEvent = event as Message;
const textParts = messageEvent.parts.filter((p): p is TextPart => p.kind === 'text');
const textContent = textParts.map(p => p.text).join('\n');
chatEvent = { id: messageEvent.messageId, role: "agent", content: textContent, type: 'message' };
agentMessageForHistory = { ...messageEvent };
} else if ((event as TaskArtifactUpdateEvent).kind === "artifact-update") {
const updateEvent = event as TaskArtifactUpdateEvent
const textParts = updateEvent.artifact.parts.filter((p): p is TextPart => p.kind === 'text');
const textContent = textParts.map(p => p.text).join('\n');
// not ref message id
chatEvent = { id: updateEvent.artifact.artifactId, role: "agent", content: textContent, type: 'message' };
agentMessageForHistory = { kind: 'message', role: 'agent', messageId: chatEvent.id, parts: [{kind: 'text', text: textContent}] };
} else {
console.warn("unknow event:", event);
}
const encoder = new TextEncoder();
if (chatEvent) {
const data = JSON.stringify(chatEvent);
controller.enqueue(encoder.encode(data + '\n'));
}
if (agentMessageForHistory) {
sessionHistory.push(agentMessageForHistory);
}
}
} catch (error) {
if (error instanceof Error) {
console.error("Error in A2A stream processing:", error);
const errMessage: ChatMessage = { id: uuidv4(), role: "system", content: `Backend Error: ${error.message}`, type: "error" };
controller.enqueue(JSON.stringify(errMessage) + '\n');
}
} finally {
controller.close();
}
},
});
return new Response(responseStream, {
headers: {
'Content-Type': 'application/json; charset=utf-8',
'X-Content-Type-Options': 'nosniff',
},
});
} catch (error) {
console.error('Error in API route:', error);
return new Response(JSON.stringify({ error: 'Internal Server Error' }), { status: 500 });
}
};ベクトル検索による記事検索
bigqueryに格納されているembeddingに対してベクトル検索し、関連ドキュメントを表示する
こちら特筆することはないが、embedding作成はこちらの記事(https://blog.uni-3.app/dbt-manage-bq-embedding )で説明している
- システム構成

githubのデータソースをワークフローにて転送。bigquery MLにてembedding取得。画面からの検索クエリを入力としてベクトル検索し、ブログ内の関連記事を取得する
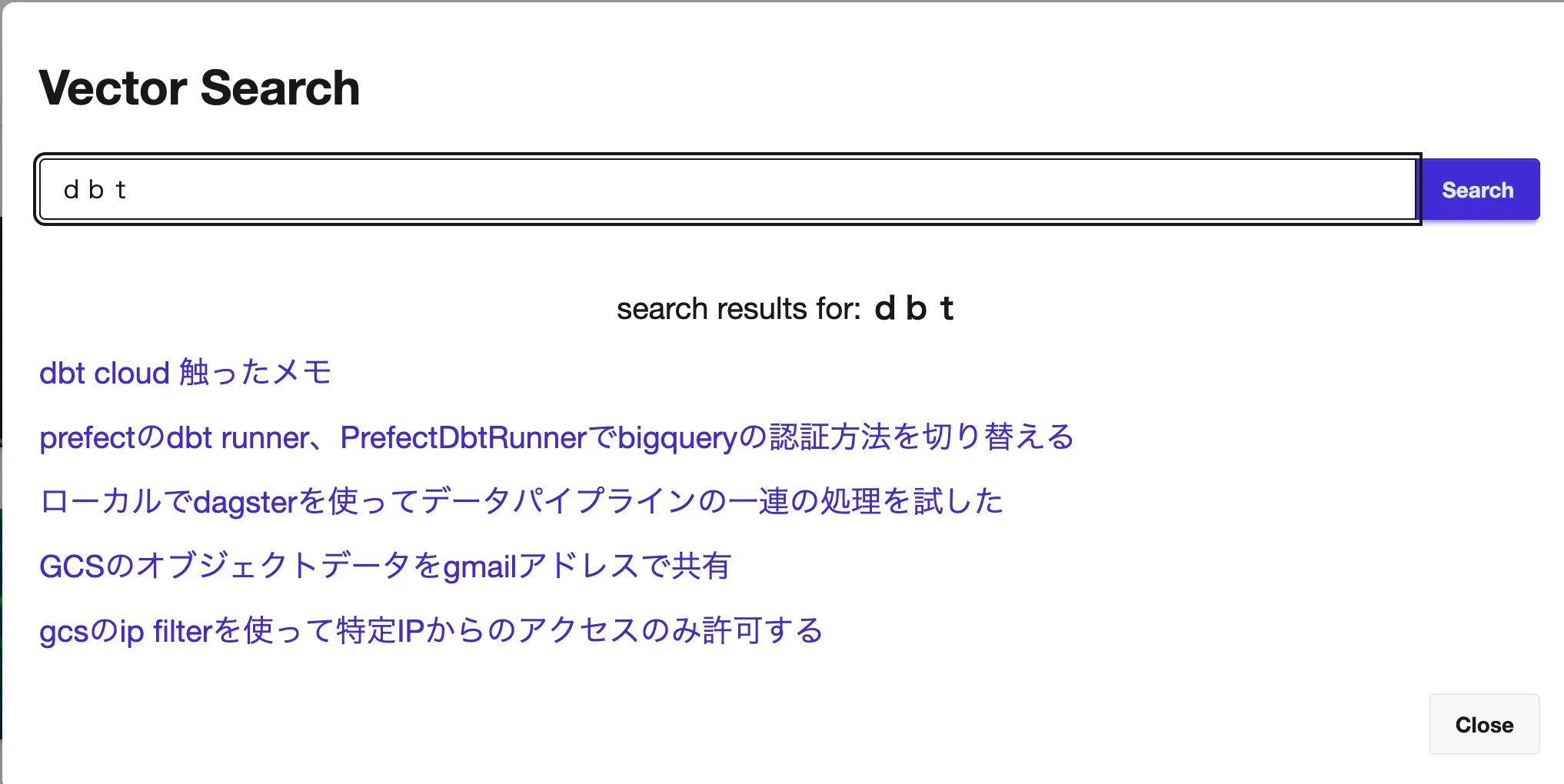
- 画面
検索モーダルはこんな感じ。サイトからはヘッダー2段目右側Vector Searchボタンから検索できる
実装
api(ベクトル検索実行)コードだけおいておく。単純にbigqueryで検索クエリ実行して返り値を返すだけ。コンポーネントはmodal使っており、コードが長くなったので割愛
export const prerender = false;
import type { APIRoute } from "astro";
import { BigQuery } from "@google-cloud/bigquery";
export interface SearchResult {
slug?: string;
title?: string;
}
export const GET: APIRoute = async ({ url, locals }) => {
const searchQuery = url.searchParams.get("query");
if (!searchQuery) {
return new Response(JSON.stringify({ error: "Search query is required" }), {
status: 400,
headers: { "Content-Type": "application/json" },
});
}
try {
const env = Object.keys(locals.runtime.env).length
? locals.runtime.env
: import.meta.env;
const keyFileJsonBase64 = env.GCP_KEYFILE_JSON_BASE64;
if (!keyFileJsonBase64) {
return new Response(
JSON.stringify({
error:
"Missing required environment variables. cannot query to vector search.",
}),
{
status: 500,
headers: { "Content-Type": "application/json" },
}
);
}
const credentials = JSON.parse(atob(keyFileJsonBase64));
const bigquery = new BigQuery({
credentials: credentials,
});
const datasetId = env.BIGQUERY_DATASET || "embeddings_dataset";
const tableId = env.BIGQUERY_TABLE || "embeddings_table";
const modelDatasetId =
env.BIGQUERY_MODEL_DATASET || "ml_models_dataset";
const modelTableId =
env.BIGQUERY_MODEL_TABLE || "embedding_model_table";
// top 5件取得
const query = `
SELECT
-- 記事データ表示用
base.slug,
base.title
FROM
VECTOR_SEARCH(
TABLE \`${datasetId}.${tableId}\`,
'ml_generate_embedding_result',
(
SELECT ml_generate_embedding_result, content AS query
FROM ML.GENERATE_EMBEDDING(
MODEL \`${modelDatasetId}.${modelTableId}\`,
(SELECT @searchQuery AS content),
STRUCT(256 AS output_dimensionality)
)
),
top_k => 5
)
`;
const options = {
query,
params: { searchQuery },
};
const [rows] = await bigquery.query(options);
return new Response(JSON.stringify(rows), {
status: 200,
headers: { "Content-Type": "application/json" },
});
} catch (error) {
console.error("Error during vector search:", error);
return new Response(
JSON.stringify({
error: "Failed to search",
details: error.message,
}),
{
status: 500,
headers: { "Content-Type": "application/json" },
}
);
}
};どちらも、おおよそ内部のコンテンツ(ブログ記事)に対して検索かけてるのでragといっていいだろうか
とりあえず検索エンジンを構築せず、自前で記事を適当に検索する機能がほしいとなったときに考えたものを実装してみた
基本的にサーバー、クエリの利用料金のみなので、コスト面でもそれなりに気が楽
agent構築も、gemini apiには無料枠があり、試すことができて助かる
おまけ
brave search周りの規約の確認
content searchでは、brave searchを用いて関連ページを取得している。規約も調べたのでまとめておきたい
google search apiは検索結果の要約を認めているかなどの規約周りで少し怪しい部分がある。そのあたりの用途について明確にしているbrave searchを使う
brave searchの無料プランにて、
検索結果の要約などの加工もOKのプランはdata for aiという項目。こちらをsubscriptionした(クレカ情報登録必須)
プランに関してはこちら
規約などを書いているのはこちら
- https://api-dashboard.search.brave.com/privacy-policy
- https://api-dashboard.search.brave.com/terms-of-service
実装
ついでに実際のtoolとして実装したコードものせておく。単純に特定のドメイン検索クエリを組み立てて、実行しているだけ。強いて言うならこの部分が肝
bs = BraveSearch(api_key=api_key)
site_specific_query = f"{query} site:{domain}"
...
response = await bs.web(WebSearchRequest(q=site_specific_query, count=num_results), retries=1, wait_time=5)
検索時に設定できるパラメータはこちらを参照した
https://api-dashboard.search.brave.com/app/documentation/web-search/query
import os
import asyncio
from pydantic import BaseModel
from typing import List
from brave_search_python_client import BraveSearch, WebSearchRequest
class SearchResult(BaseModel):
"""
Data model for a single search result.
The `description` field holds the initial search snippet, which is later
replaced by the full summary from the summarizer agent.
"""
url: str
title: str
description: str
class SearchResultList(BaseModel):
"""Data model for the final list of search results."""
articles: List[SearchResult]
async def search_brave(query: str, domain: str, num_results: int) -> List[SearchResult]:
"""
Performs a Brave search for the given query within a specific domain.
Args:
query: The search query (e.g., keywords).
domain: The domain to restrict the search to (e.g., "example.com").
num_results: The desired number of search results.
Returns:
A list of search results as SearchResult objects.
Raises:
ValueError: If the BRAVE_SEARCH_API_KEY environment variable is not set.
Exception: For other errors during the search process.
"""
api_key = os.getenv("BRAVE_SEARCH_API_KEY")
if not api_key:
raise ValueError("BRAVE_SEARCH_API_KEY environment variable not set.")
bs = BraveSearch(api_key=api_key)
site_specific_query = f"{query} site:{domain}"
print("input query to search engine", site_specific_query)
try:
response = await bs.web(WebSearchRequest(q=site_specific_query, count=num_results), retries=1, wait_time=5)
if not response.web or not response.web.results:
return []
return [
SearchResult(
title=result.title,
url=result.url,
description=result.description,
)
for result in response.web.results
]
except Exception as e:
print(f"An error occurred during Brave search: {e}")
raise
async def main():
test_query = "python machine learning"
test_domain = "realpython.com"
print(f"Searching for '{test_query}' on '{test_domain}'...")
try:
results = await search_brave(test_query, test_domain, num_results=3)
if results:
print("Found URLs:")
for r in results:
print(f"- {r.title}: {r.url}")
else:
print(f"No results found.\n")
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == '__main__':
from dotenv import load_dotenv
load_dotenv()
asyncio.run(main())もしかしたら、brave search mcp serverを使っても実現可能やもしれないが、確実に指定したsiteについて検索してほしいのでsdkにする