dbtでbigqueryのembeddingテーブルを作成する
ブログコンテンツのembedding作成しようと思ったが、記事の更新や作成に追従してembeddingも更新させたかったので、dbtにて管理することにした
incrementalに更新させることに成功した
実装
ほぼモデルの設定の説明。以下公式ドキュメントの通り設定していった
https://cloud.google.com/bigquery/docs/generate-text-embedding?hl=ja#bq
embeddingモデル定義作成
bigqueryが利用するモデルの接続設定までは公式ドキュメントの通り
こちらもdbtのoperationなどで管理してもいいが、SQLでもなかったりするし、ワンショットでもあるのでやめておく
- model保存先データセット ml_modelsという名称で作成
bq --location=US mk -d ml_models- vertex aiにあるmodelとの接続作成 bqml_vertex_connectionという名称で作成
bq mk --connection \
--location=US \
--project_id=<your-gcp-project-id> \
--connection_type=CLOUD_RESOURCE \
bqml_vertex_connection- 接続に使うサービスアカウントの確認
bq show --format prettyjson --connection US.bqml_vertex_connection
{
"cloudResource": {
"serviceAccountId": "bqcx-xxxx@gcp-sa-bigquery-condel.iam.gserviceaccount.com"
},
"creationTime": "1755074840000",
"lastModifiedTime": "175507484000",
"name": "projects/xxxx/locations/us/connections/bqml_vertex_connection"
}サービスアカウントにvertex aiの権限を付与
gcloud projects add-iam-policy-binding {project_id} --member='bqcx-xxxx@gcp-sa-bigquery-condel.iam.gserviceaccount.com' --role='roles/aiplatform.user'
Updated IAM policy for project [{project_id}].- embeddingモデル作成 bigquery consoleから実行
CREATE OR REPLACE MODEL `ml_models.embedding_model`
REMOTE WITH CONNECTION `US.bqml_vertex_connection`
OPTIONS (ENDPOINT = 'gemini-embedding-001');利用可能なモデルは以下より参照
https://ai.google.dev/gemini-api/docs/embeddings?hl=ja#model-versions
embedding作成
dbt のincremental modelとして作成。最終更新日(last_modified)を持たせることで、追加、更新したコンテンツに対してembeddingを再作成する
名称はblog_content_embeddings.sql
GENERATE_EMBEDDING句のお作法としてcontent列がembedding生成対象となる。他のカラムはドキュメント検索時に必要なメタデータとして持っておく
struct句のoutput_dimensionalityにてembeddingの次元数の設定ができる
{{
config(
materialized='incremental',
unique_key='slug',
incremental_strategy='merge'
)
}}
WITH c AS (
SELECT
content,
title,
slug,
last_modified
FROM {{ ref('stg_blog_content') }}
{% if is_incremental() %}
WHERE last_modified > (SELECT COALESCE(MAX(last_modified), TIMESTAMP('1970-01-01')) FROM {{ this }})
{% endif %}
)
SELECT
content,
title,
slug,
last_modified,
ml_generate_embedding_result
FROM (
SELECT *
FROM ML.GENERATE_EMBEDDING(
MODEL `ml_models.embedding_model`,
(SELECT * FROM c),
STRUCT(
TRUE AS flatten_json_output,
'RETRIEVAL_DOCUMENT' AS task_type,
256 AS output_dimensionality
)
)
)外部接続として作成したモデルに接続するため、dbtを実行するアカウントにはroles/bigquery.connectionUser権限が必要
ドキュメント取得
vector search関数を使って検索をかけるML.DISTANCE句使わなくてよくなった。
SELECT
query.query,
base.slug,
base.title,
distance
FROM VECTOR_SEARCH(
TABLE `blog.blog_content_embeddings`, 'ml_generate_embedding_result',
(
SELECT ml_generate_embedding_result, content AS query, *
FROM ML.GENERATE_EMBEDDING(
MODEL `ml_models.embedding_model`,
(SELECT 'パイソン' AS content),
struct(256 AS output_dimensionality)
)
),
top_k => 5, options => '{"fraction_lists_to_search": 0.01}')
output_dimensionalityにはembedding作成時のものと同じ値を指定する必要がある
結果は以下。カタカナで検索してもpythonらしき記事が取得できている
query slug title distance
パイソン colab-exec-py google colaboratoryで引数を指定して.pyファイルを実行 0.2635045882458244
パイソン poetry-make-package poetryでpython packageをgithub urlで公開 0.26985315516559566
パイソン gitpod-how-to-python-in-terminal gitpodで事前にpythonライブラリをインストールする 0.27400421610605774
パイソン nodebrew-install デフォルトでpython3系を使っているとnodeのインストールに失敗する 0.27573325102563262
パイソン pytrends-food pytrendsでgoogle trendのデータを取得してみる 0.27740370126483022本来ならVECTOR INDEX句を使ってindexを作成したテーブルに対して利用するものであるが、index作成に最低5000コンテンツ必要だったため、作成できなかった。がクエリは実行できる(その場合プルートフォース検索になる)
作ったあとにdbt mlを使ってモデル作成の実行もできるみたいだが、モデル作成後存在に気づいたのでやめた。embedding周りのドキュメントないし、まぁいいや
https://hub.getdbt.com/kristeligt-dagblad/dbt_ml/latest/
サムネイル用にクラスタリングした
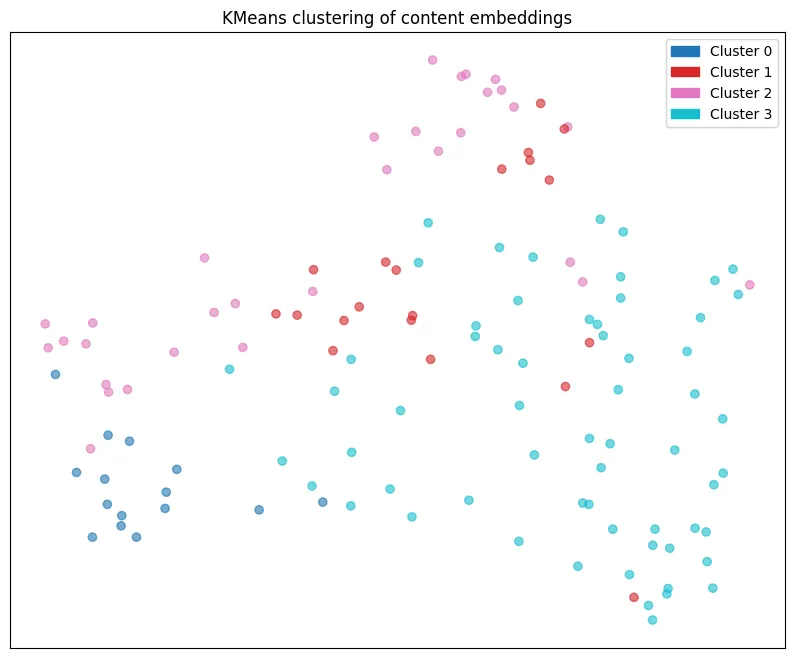
見た感じ、0は数式多め。1はgcpなど触ってみた。2はpythonや可視化などコードや解説多め。3はその他の記事で分かれていた
料金
embeddingモデルにはgeminiを用いたので、embeddingの取得料金はトークン数に依る
embeddingの作成は1回193,198 tokenだった。全コンテンツの文字数は516,628
Batch requests: $0.00012
per 1000 tokenなので
およそ3円。実際の請求画面でもおよそこの金額だった
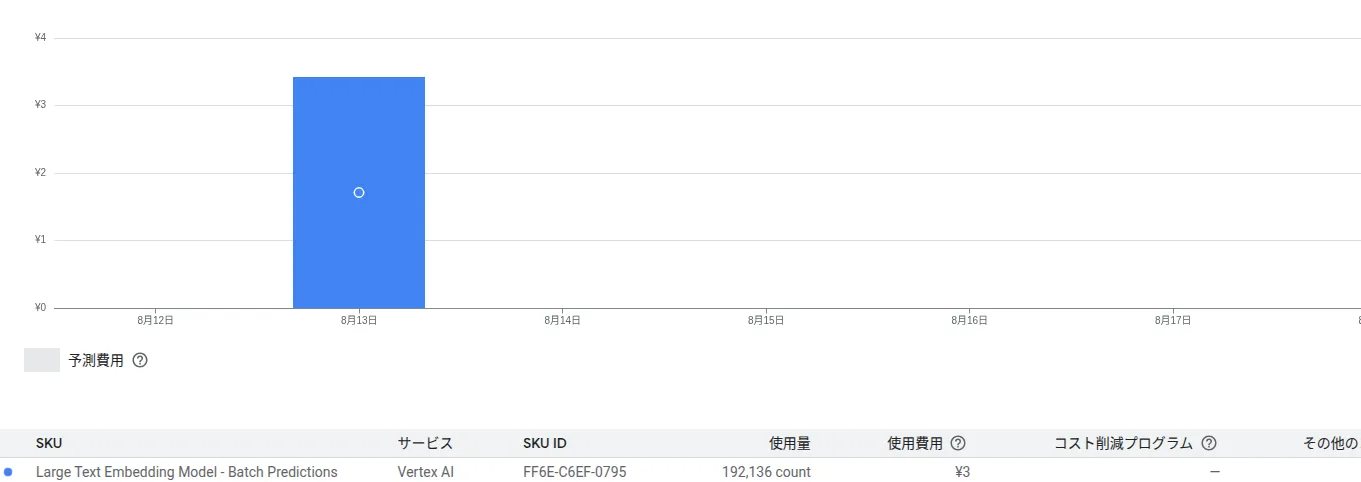
このあたりから入力文字のトークン数の確認ができる
おまけ
vector index作成
コンテンツ数がたりないため作成できなかったが、調べたのでメモ
Total rows 120 is smaller than min allowed 5000 for CREATE VECTOR INDEX query with the IVF index type. Please use VECTOR_SEARCH table-valued function directly to perform the similarity search.
ドキュメントとクエリの距離を都度計算するとコストや時間がかかるため、vector indexを作成することでドキュメント側のベクトルを一定にまとめたものを作る。ベクトル検索における近似検索という技術のこと
index作成のタイミングはbigqueryのsearch indexと同じで、都度(内部で非同期に作成)のようす
↓指定により、embedding列にvector indexが作成される。またstoringにメタデータとして使用する列を書いておく
CREATE OR REPLACE VECTOR INDEX blog_content_embedding_vector
ON `blog.blog_content_embeddings`(ml_generate_embedding_result)
STORING(slug, title)
OPTIONS(index_type = 'IVF',
distance_type = 'COSINE',
ivf_options = '{"num_lists":20}')VECTOR INDEX句のリファレンス
- https://cloud.google.com/bigquery/docs/vector-index?hl=ja
- https://cloud.google.com/bigquery/docs/reference/standard-sql/data-definition-language#create_vector_index_statement
optionsの解説
index_type
IVF or TREE_AH を指定できる
下手に解説するより公式説明のほうを見るほうが良さそう
とりあえず、TREE_AHは大規模データ対象のようなのでIVFにする
https://cloud.google.com/bigquery/docs/vector-index?hl=ja#choose-vector-index-type
IVFは全文検索のアルゴリズムで、kmeansよりクラスタリングして、クラスターの近傍のみスキャンすることでコストを削減する
https://zenn.dev/m_nakano_teppei/articles/22baa496b9ac3b
ivf_options
指定できるのはnum_listsのみ。ベクトルはクラスタの重心の中で最もに近いものに割り当てられる。この割り当て先をリストと呼んでいる。kmeansのクラスタ数かな
document取得
indexを利用しない場合は以下のようなプルートフォースoptionを入れる
SELECT
query.query,
base.slug,
base.title,
distance
FROM VECTOR_SEARCH(
TABLE `blog.blog_content_embeddings`, 'ml_generate_embedding_result',
(
SELECT ml_generate_embedding_result, content AS query, *
FROM ML.GENERATE_EMBEDDING(
MODEL `ml_models.embedding_model`,
(SELECT 'パイソン' AS content),
struct(256 AS output_dimensionality)
)
),
top_k => 5, options => '{"use_brute_force":true}')
vertex ai vector searchについて
bigqueryに作成したembeddingからvertex aiのほうのvector searchサービスの方にimportもできるらしい
こちらのサービスのほうがリッチな検索設定を行えるが、index管理に加えクエリ料金もかかり、当然コストもあがるので作成は見送った
https://cloud.google.com/vertex-ai/docs/vector-search/import-index-data-from-big-query?hl=ja
参考
- vector search
https://cloud.google.com/bigquery/docs/reference/standard-sql/search_functions#vector_search
- embedding pricing
https://cloud.google.com/vertex-ai/generative-ai/pricing#embedding-models
- vertex ai search
https://zenn.dev/cloud_ace/articles/vertex-ai-vector-search-hybrid-search