spotifyのapiを使ってデータを取得してみた。 ロック音楽の年代ごとの特徴をみてみる
環境
- python: 3.7
- spotipy: 2.9.0
- tableau: 2020.2.2
データ
spotify apiから取得できるplaylist情報と含まれるtrackの楽曲情報を用いる
spotifyが作成したxx年代rock的なplaylistを使用した
取得できる楽曲情報
Get Audio Features for a Track | Spotify for Developers
Get a Track | Spotify for Developers
を参考に。14個あった
-
duration_ms : トラックの長さ(ms)
-
popularity : 人気度合い。累計と最近の再生数から推定される。1~100の値を取る
-
key : キーの高さ。キーが検出できない時は-1
-
mode : メジャー(1)またはマイナー(0)。
-
loudness : トラックの全体的な音量。0~-60(db)の値を取る
-
time_signature : 拍子のこと
-
tempo : テンポ(BPM)
-
acousticness : アコースティック度合い。0.0~1.0の値を取る
-
danceability : ダンサブル度合い。0.0~1.0の値を取る
-
energy : エネルギッシュ度合い。0.0~1.0の値を取る
-
valence : ポジティブ度合い。0.0~1.0の値を取る
-
liveness : 音源のライブっぽさ。0.0~1.0の値を取る
-
instrumentalness : トラックの中で、声が入っていない度合い。0.0~1.0の値を取る
-
speechiness : 喋ってる度合い。0.0~1.0の値を取る
全て学習データを作って判定しているのだろうか
実装
- playlistを取得し、trackの特徴を取得
def get_playlist_tracks(df, sp):
df_out = pd.DataFrame()
for row in df.itertuples(index=False):
items = sp.playlist_tracks(row[1], limit=100)['items']
# merge playlist_id df&df_tracks
df_tracks = df.merge(get_tracks(items, row[1]), on='playlist_id')
# merge track_id df&df_features
df_features = df_tracks.merge(get_audio_features(df_tracks, sp), on='track_id')
df_out = df_out.append(df_features)
return df_out
def get_tracks(items, playlist_id):
#for item in res_tracks['items']:
l = []
for item in items:
track = item['track']
track_id = track['id']
artist_name = track['artists'][0]['name']
track_name = track['name']
release_date = track['album']['release_date']
track_popularity = track['popularity']
l.append([playlist_id, track_id, artist_name
,track_name, release_date, track_popularity])
time.sleep(1)
cols = ['playlist_id', 'track_id', 'artist_name', 'track_name'
,'release_date', 'track_popularity']
df = pd.DataFrame(l, columns=cols)
#print(track)
return df
# 50ごとに取得
def get_audio_features(df, sp, limit=50):
df_features = pd.DataFrame()
for i in range(0, int(len(df) / limit)+1):
tracks = list(df['track_id'].iloc[i*limit:i*limit+limit])
#print('track len', len(df))
#print(f'range: {i*limit}~{i*limit+limit}')
df_features = df_features.append(pd.DataFrame(sp.audio_features(tracks=tracks)))
time.sleep(1)
df_features.rename(columns={'id': 'track_id'}, inplace=True)
#print('len df_feat', len(df_features))
#print('df_feat cols', df_features.columns)
return df_features
import pandas as pd
import time
import spotipy
# init spotify api
client_id = '240xxxxx'
client_secret = 'a62xxxxxxxx'
client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
# playlists
playlist_cols = ['title', 'playlist_id']
playlists = [['70s Rock Anthems', '37i9dQZF1DWWwzidNQX6jx']
,['Women of Rock', '37i9dQZF1DXd0ZFXhY0CRF']
,['80s Rock Anthems', '37i9dQZF1DX1spT6G94GFC']
,['60s Rock Anthems', '37i9dQZF1DWWzBc3TOlaAV']
,['90s Rock Anthems', '37i9dQZF1DX1rVvRgjX59F']
,['00s Rock Anthems', '37i9dQZF1DX3oM43CtKnRV']
]
df_playlist = pd.DataFrame(playlists, columns=playlist_cols)
# 検索してplaylistの詳細情報を追加
%time df_all = get_playlist_tracks(df_playlist, sp
df_all.to_csv('./spotify_playlists.csv', index=False)
playlistの検索とidの取得は以下のようなスクリプトで行った
# 検索
query = "10s"
results = sp.search(q=query, limit=20, type='playlist', offset=1)
for idx, track in enumerate(results['playlists']['items']):
print(idx, track['owner']['display_name'], track['id'], track['name']
, track['tracks']['total']
, track['external_urls']['spotify']
)
print(track['description'])
可視化
ダッシュボードは↓
https://public.tableau.com/app/profile/yuni7627/viz/spotify_rock/clustertracks
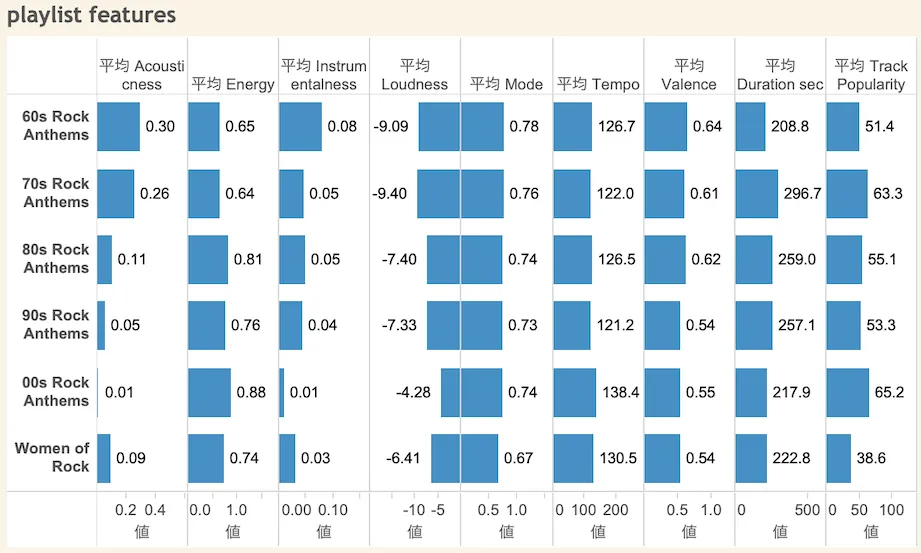
特徴量のうちplaylistごとに違いの大きいものを出してみた
時代が進むにつれアコースティック感は下がっていく、 エネルギーは大きく、インストゥルメンタルさは下がっていく。loudness(騒がしさ)も小さくなっていく。テンポは上がっていき、楽曲長さもだんだん短くなっていく popularityは70年代と00年代が特に大きい
女性のロックはアコースティック的であると言える
こちらの記事によるとspotifyユーザは65%が34歳以下を占めるらしい
popularityは00年代が大きいのはなんとなく納得
クラスター
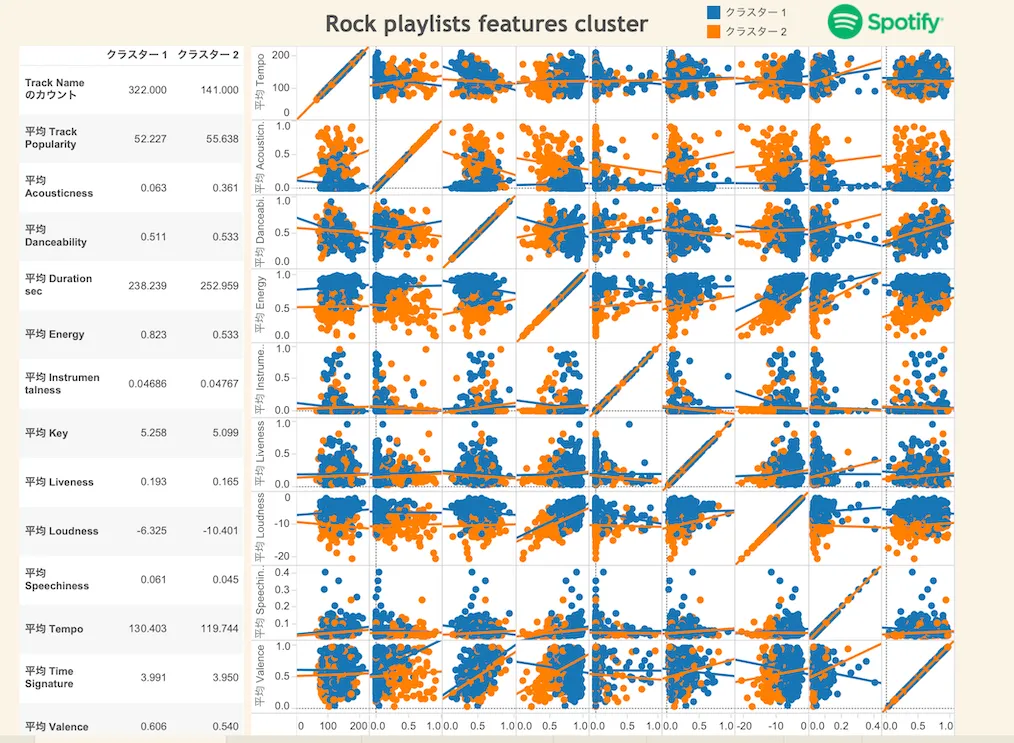
違いのありそうな特徴量を元にクラスター分析した
騒がしめ(エネルギッシュで音量が大きめ)の楽曲と、やや大人しめの楽曲(アコースティック高めでキー、テンポが低め)にクラスタリングされた