pythonでデータを作成し、tableauにて可視化を行った
作ったもの
scotch whiskyの味の特徴と蒸留所の場所を可視化するtableauノートブックを作成した
スコッチウイスキーについて、似ている風味のものや蒸留所(Distillery)の地図上でマッピングするダッシュボードを作成した
python
データ取得、分析、加工までgoogle colaboratoryにて行った
データについて
元データはwhisky taste classificationを使用。このデータセットには86種類のスコッチウイスキーについてDistillery(蒸留所)、位置情報、12種類のカテゴリ(sweetness, smoky, nuttyなど)について0-4で得点を付けたもの、を含む
各カテゴリは何やら風味について言及しているが、bodyは味というか飲み口みたいなものを表している。bodyは口の中に残る余韻のことを示しており、大きいほど余韻が大きいらしい
データ読み込み用スクリプト
import pandas as pd
data_url = 'https://outreach.mathstat.strath.ac.uk/outreach/nessie/datasets/whiskies.txt'
df = pd.read_csv(data_url) 前処理 元データの特徴をまとめる
元データには12種類の特徴量があったが、whisky wheelの区分を参考にしてカテゴリ数を12から8に減らしている(因子分析にかけるとき、なるべく次元数を減らしたかったため)。
具体的には以下のようにまとめて、これらの和を取ったものを新たな特徴量とした
body_cols = ['Body']
winey_cols = ['Winey', 'Nutty']
central_cols = ['Malty']
feinty_cols = ['Honey', 'Tobacco']
peaty_cols = ['Medicinal', 'Smoky']
floral_cols = ['Floral']
fruity_cols = ['Fruity', 'Sweetness']
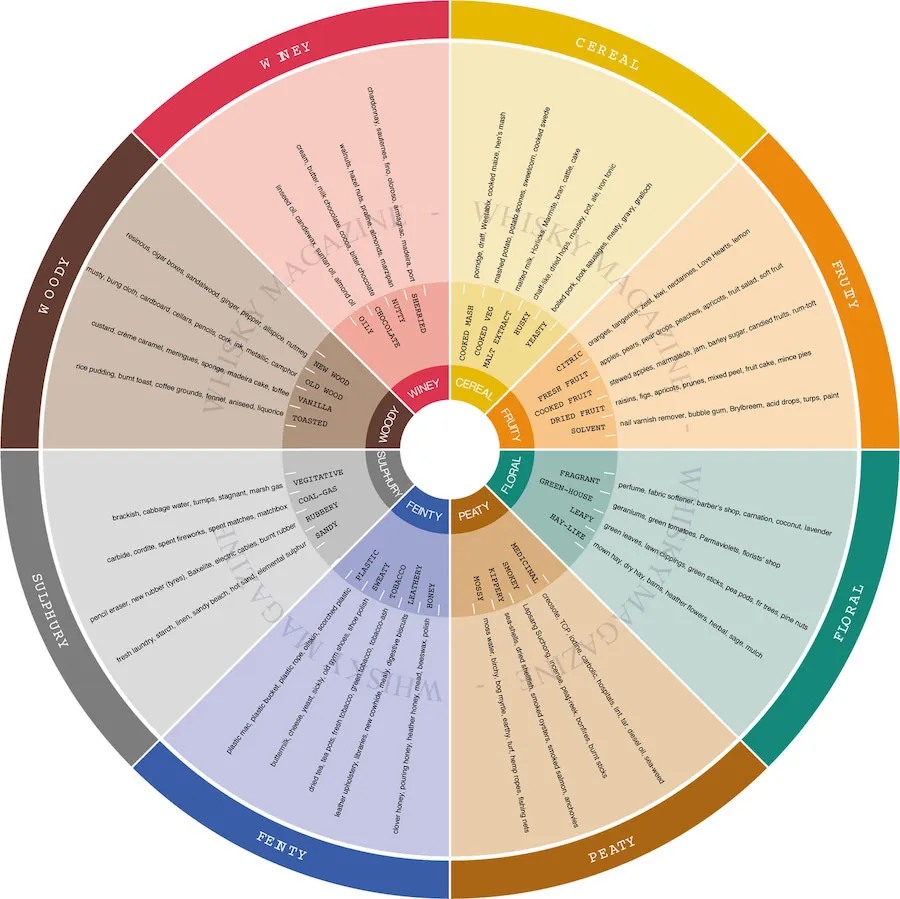
woody_cols = ['Spicy']whisky wheelはこちらを使用した
因子分析(factor analysis)で因子抽出
各特徴量の関係を次元圧縮し、指定した数の因子としてまとめる。 2次元の散布図に表示したかったので、因子数は2とした
モデルの各因子負荷量をみてみる
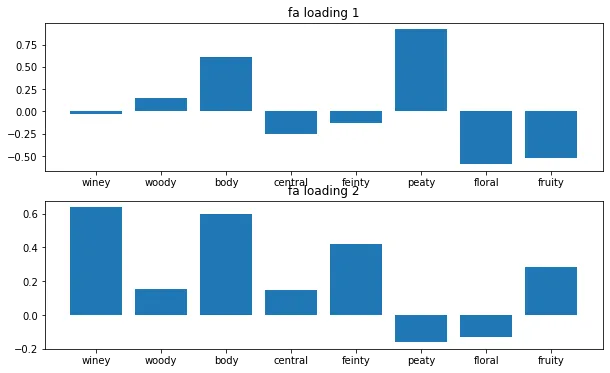
第一因子はpeaty&bodyが高く、floral&fruityは低くなっている
第二因子はwiney&fruity&bodyが高く、peaty&floralは低くなっている
また、tableauワークブックにて因子のplotをみると、右上には点がない。peatyでwineyなウイスキーはない、ということなのだろうか
また、相関行列のplotも出してみた

結構因子の特徴を表現している。wineyもしくはpeatyだとbodyは高いらしい
実行スクリプトは以下
- モデル作成
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.decomposition import FactorAnalysis as FA
# 因子分析
def fa_and_plot(X, target, n_components=2):
ss = StandardScaler()
fa = FA(n_components=n_components, max_iter=500)
pl = Pipeline([("scaler", ss), ("fa", fa)])
x = pl.fit_transform(X)
return pl['fa'], x
val_cols = ['winey', 'woody', 'body',
'central', 'feinty', 'peaty',
'floral', 'fruity']
fa, x_fa = fa_and_plot(df[val_cols], df['Distillery'].values, n_components=2)- 因子負荷量のplot
# 因子負荷量
plt.figure(figsize=(10, 6))
plt.subplot(2, 1, 1)
plt.bar(list(df[val_cols].columns), fa.components_[0])
plt.title('fa loading 1')
plt.subplot(2, 1, 2)
plt.title('fa loading 2')
plt.bar(list(df[val_cols].columns), fa.components_[1])
plt.show()- 相関行列のplot
import seaborn as sns
sns.heatmap(df[val_cols].corr(), vmax=1, vmin=-1, center=0)
plt.show()
後処理 tableau表示用に加工してspread sheetへ出力
レーダーチャートで表示するため、ダミーのkey(ここではz_body)を追加した
また、データは縦持ちにしている
# 出力データ加工用
id_cols = ['RowID', 'Distillery', 'Postcode', ' Latitude', ' Longitude', 'x0_fa', 'x1_fa']
# tableauでレーダーチャートに表示するためのカラム
df_fa2 = df_fa.copy()
df_fa2['z_body'] = df_fa2['body']
df_melt = df_fa2.melt(value_vars=val_cols+['z_body'], id_vars=id_cols, var_name='key')
# tableauで計算するためにカテゴリごとにidをつける
df_melt['key_id'] = df_melt['key'].astype('category').cat.codes + 1spread sheetへの書き込み用スクリプト
from google.colab import auth
from oauth2client.client import GoogleCredentials
import gspread
import gspread_dataframe as gs_df
# 認証処理
auth.authenticate_user()
gc = gspread.authorize(GoogleCredentials.get_application_default())
# 一つ目のワークシートへ書き込み
worksheet = gc.open('class_whiskey').get_worksheet(0)
gs_df.set_with_dataframe(worksheet, df_melt)tableau
Tableau Publicで作成し、公開した
詰まった部分を残しておく
tableauでpostcode(郵便番号)をマッピング
mapをtableauで表示させようとしても、このままではLatitude Longitudeの表記方法が異なるため使えず。また、Postcodeも分割してoutcodeをimportしないとできなかった
こちらの記事を参考にした
UK Postcode mapping in 5 minutes - The Information Lab
OutCodesよりOUTCODE.csvをダウンロードし、tableauにimportする
これにより、スペースで分割したPostcodeの前半部分を地理データとして用いると、自動で座標変換されmapデータとして表示できる
レーダーチャート作成
計算フィールドとチャートは、以下のページを参考に作った。表示用にデータを入れたりしないといけないのが辛かった
参考
-
Rによるデータサイエンス
因子分析の例を参考にした -
sklearn.decomposition.FactorAnalysis — scikit-learn 0.22.1 documentation