qiita organizationsにあるデータをクローリングして人気のタグや規模の大きい組織をtableauで可視化した
データセット
https://qiita.com/organizations ページを起点に、登録してある組織の情報を取ってきた
取得したデータは以下の通り
detail_page_url,logo_url,name,n_posts,n_goods,org_url,org_email,org_addr,org_description,org_content,n_member,member_url_list,tag_name,tag_icon,tag_post,tag_good
組織の名前、投稿数、LGTM数、投稿されているタグtop5など
タグは投稿数の多い順で5つ表示してあることに注意
とても雑に書いたスクリプトも一応上げてあるGitHub - uni-3/crawler: python
可視化
タグと紐づく組織の発見や組織の特徴を閲覧できるように作成した。ダッシュボードは↓
探索
人気のタグは一般的な言語が多い。たくさん投稿されて、総合的にLGTM数も多くなるためと思われる
1投稿あたりのLGTM数をみるとバズりやすそうなタグや投稿の特徴がなんとなくわかりそうな気もする
組織による違い
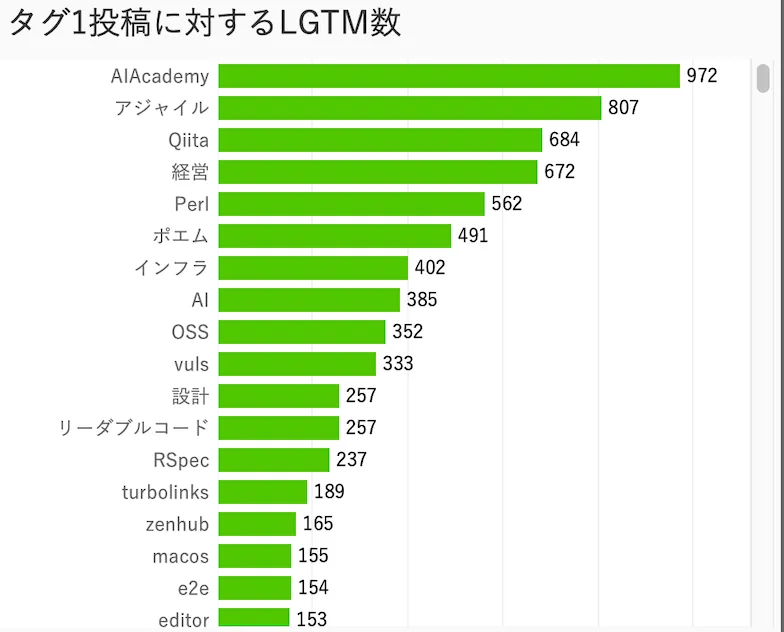
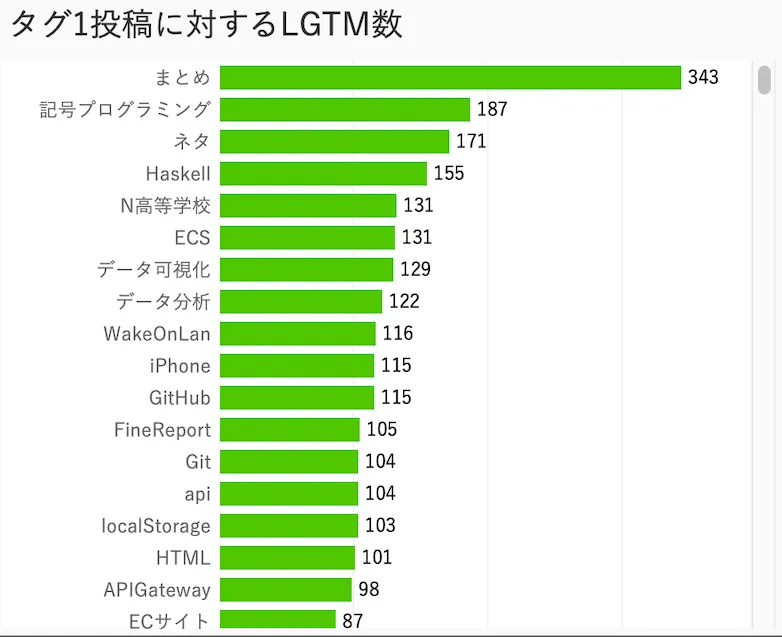
組織名に株式会社と入っているかそれ以外で分けてみた
結構LGTMを稼いでいるタグの顔ぶれが変わる。株式会社のみだとアジャイルや設計、OSS、インフラなど、組織での開発に関係しそうなタグが多い 株式会社以外だとプログラミングや具体的なサービス名、まとめなど技術に関係しそうなタグが多い
- 株式会社のみ
- 株式会社以外
クラスター分析
組織ごとに投稿数、LGTM数を使ってクラスターに分けてみる
tableauで行った。クラスター分析はkmeansが適用される。結果は以下のようになった
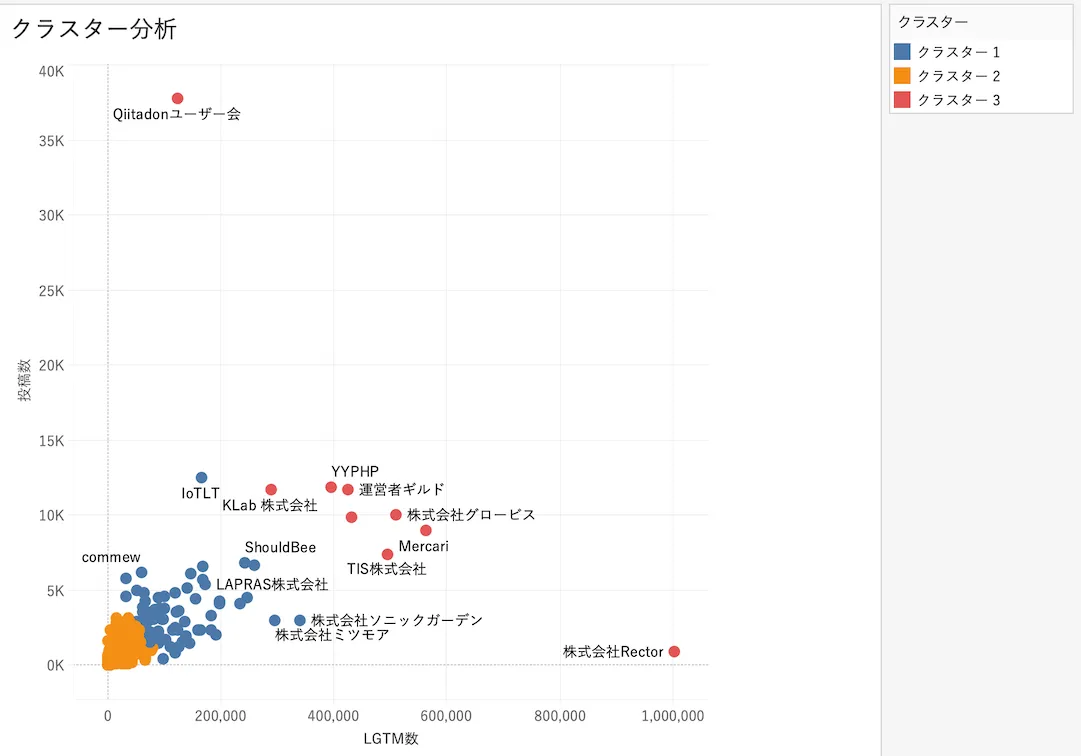
クラスタリングの入力
変数: LGTM数 の合計
投稿数 の合計
詳細レベル: 組織名
スケーリング: 正規化
サマリー診断
クラスターの数: 3
ポイントの数: 922
グループ間の 2 乗の合計: 3.8286
グループ内の 2 乗の合計: 1.8096
2 乗の総合計: 5.6382
中央値
クラスター 項目の数 LGTM数 の合計 投稿数 の合計
クラスター 1 70 1.2104e+05 3442.3
クラスター 2 843 9976.9 483.07
クラスター 3 9 4.7073e+05 12242.0
クラスター化されていません 0 分布が偏っていることからも明らかだが、一部の比較的大きい、中くらいの投稿数、LGTM数の組織と、大多数の比較的投稿数、LGTM数が小さい組織に別れる
今回はアドホックに取得してデータを保存したものを使ったが、スクリプトを定期実行するようにして自動更新するようにしたい