ブクログ - web本棚サービス という読みたい本・読んだ本を登録しておけるサービスがある。こちらに登録したデータを出力して可視化してみた
環境
- python: 3.7
- ginza: 3.1
- tableau: 2020.2.2
データ取得
ブクログにログインし、本棚からエクスポートする
出力されるcsvの列情報は以下の通り
サービスID, アイテムID, 13桁ISBN, カテゴリ, 評価, 読書状況, レビュー, タグ, 読書メモ(非公開), 登録日時, 読了日, タイトル, 作者名, 出版社名, 発行年, ジャンル, ページ数
タイトルの自然言語処理
ついでにタイトルを単語に分割したものも可視化してみる
booklogのcsvからタイトルの品詞や単語数などを取得してcsvにする処理を行う。使ったnotebookをおいておく
gist:uni-3/8f743303ffb71ecf824859ab9a7258bb
可視化
作成したダッシュボードはこちら https://public.tableau.com/app/profile/yuni7627/viz/booklog_shelf/BooklogDashboard
気になる本をとりあえず登録していくような使い方をしているので、読了ステータス周りの日数は考察できないが、閲覧用途としてはいい感じ
-
目指したこと
- 登録日時別の登録数がみたい
- 何ページくらいの本を登録しているか、そのばらつきは
- 読了した冊数と読了までの日数がわかる
- 登録した本から興味の移り変わりがわかる
ついでに自然言語処理っぽいことをして、タイトルの集計情報を閲覧できるダッシュボードも作成した
- みんな大好きワードクラウド
- 単語から興味のあるジャンル等の傾向をみて取れる
解析 単語の出現頻度の分布(zipfの法則)
tableauにて単語の出現頻度をべき分布で近似し、分析した。ダッシュボードには載せていない
ジップの法則(wikipedia)として知られている
縦軸に単語のディメンションのカウントを、横軸にそのランクを取って、両方の軸の対数にする。傾向線として累乗近似を追加することで近似式を描画すると以下のように直線上にのる
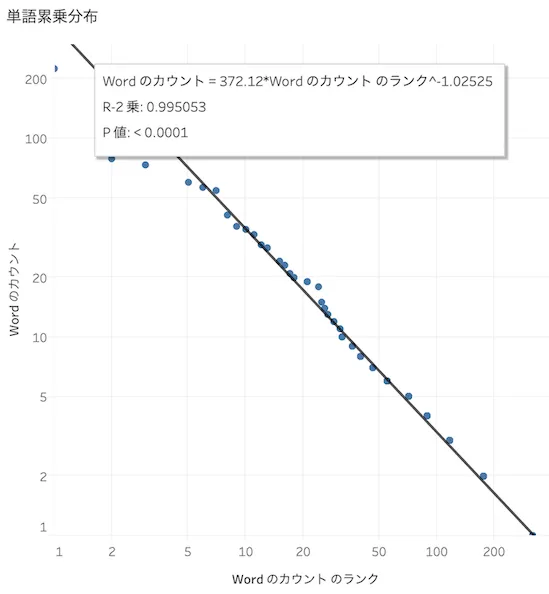
式は
と傾きはおおよそ1であった。極端な分布になっている
あとはデータの更新、処理結果の作成を自動化できるとよさそう。気が向いたらやろう