全国市販酒類調査という国税庁が毎年行っている、全国の酒類の品質や成分を報告データを可視化してみた。pdfファイルの最後の方に参考情報として載っている
どうやら酒税は酒の成分に基づいて決まるようになっているのでそういった調査をしているらしい。あとsteramlitのホスティングをherokuで試したかった
画面はこちら
実装
環境
- python: 3.8.x
- streamlit: 1.3.x
- tabula-py: 2.3.x
データソース
- ↓ページの各PDFファイルへのリンクを用いた
https://www.nta.go.jp/taxes/sake/shiori-gaikyo/seibun/06.htm
データ取得
取得したのはPDFファイルから分析等結果のページの表部分。罫線で囲まれているのでlattice=Trueを指定
import tabula
# 各ページの表をdataframeのlistとして取得
dfs = tabula.io.read_pdf(url, pages='35-38', lattice=True)グラフとかデータ集計はそんなに特殊なことをしていないので割愛する
herokuにデプロイ
requirements.txt とProcfileを作成して、デプロイ
heroku login -i
heroku create test-app
git push heroku mainmkdir -p ~/.streamlit/
echo "\
[server]\n\
headless = true\n\
port = $PORT\n\
enableCORS = false\n\
\n\
" > ~/.streamlit/config.tomlweb: sh setup.sh && streamlit run ./sake-gaikyo/app.py- javaのbuilcpack追加 tabula-pyで使っているjavaがないといわれた
JavaNotFoundError:
javacommand is not found from this Python process.Please ensure Java is installed and PATH is set forjava
↓記事を参考にbuildpackとpom.xmlを追加した
https://qiita.com/Fortinbras/items/2990f94800a51d74cd71
heroku buildpacks:add --index 1 heroku/java
heroku buildpackspom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<version>1.0-SNAPSHOT</version>
<artifactId>helloworld</artifactId>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.0.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>package</phase>
<goals><goal>copy-dependencies</goal></goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>参考
github actionsで自動デプロイ
name: deploy
on:
push:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: akhileshns/heroku-deploy@v3.12.12 # This is the action
with:
heroku_api_key: ${{ env.HEROKU_API_KEY }}
heroku_app_name: ${{ env.APP_NAME }}
heroku_email: ${{ env.EMAIL }}
env:
APP_NAME: "sake-gaikyo"
HEROKU_API_KEY: ${{ secrets.HEROKU_API_KEY }}
EMAIL: ${{ secrets.EMAIL }}gitpodで開発していて、push行う場合はworkflowの編集権限が必要。設定よりgithubの権限の編集からworkflowにチェックを入れる
参考
- https://zenn.dev/shin_shin_01/articles/53009a81728e21
- https://github.com/gitpod-io/gitpod/issues/984#issuecomment-582454483
地図上に可視化
大変だったのでメモしておく データソースに都道府県名がいたのでマップグラフしてみた
geopandasでやろうとしたけどstreamlitが未対応のようだったので altairを用いた、地図のプロットはgeojsonを探し当てればなんとかなる様子
altairのlookupDataを用いることで、値の入ったデータのdataframeと geojsonのデータを内部で結合し、値なんかをマッププロットで使用できる altairなんでもできる
コード例
import altair as alt
# geojson for japan
regions = alt.topo_feature(
'https://raw.githubusercontent.com/dataofjapan/land/master/japan.topojson', 'japan')
map = alt.Chart(regions).mark_geoshape(
stroke='black',
strokeWidth=0.1
).transform_lookup(
lookup='properties.nam_ja',
from_=alt.LookupData(df, '県名', [value_col])
).encode(
tooltip=[
alt.Tooltip('properties.nam_ja:N', title='県名'),
alt.Tooltip(f'{value_col}:Q', format='.2f')
],
color=f'{value_col}
map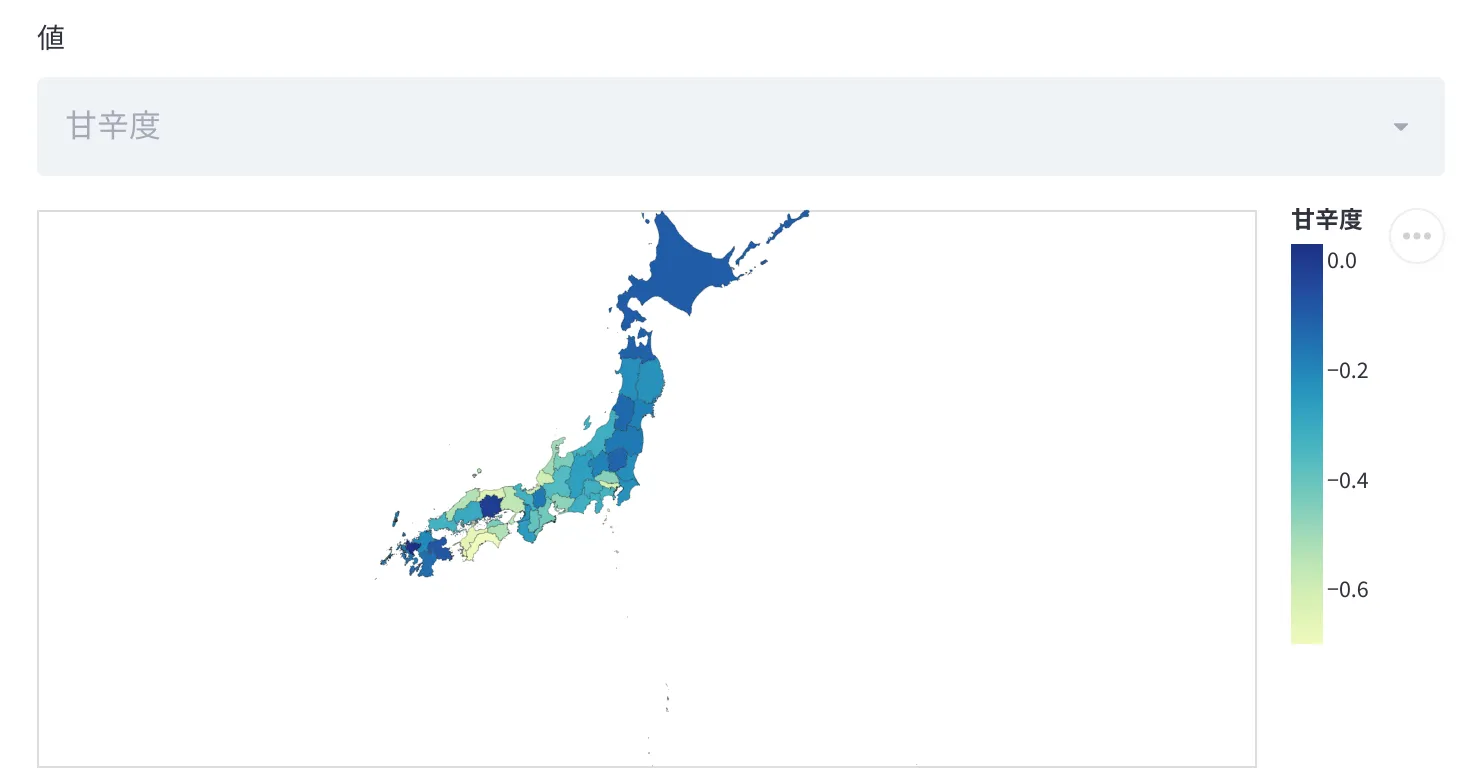
参考
- https://discuss.streamlit.io/t/maps-with-altair-and-geopandas/2953
- https://altair-viz.github.io/user_guide/transform/lookup.html
- https://qiita.com/c60evaporator/items/ac6a6d66a20520f129e6
グラフ考察
ドメイン知識がないのでなんともいえないが
吟醸酒は香りがよさそうだというのがわかったので困ったら頼んでいきたいと思った
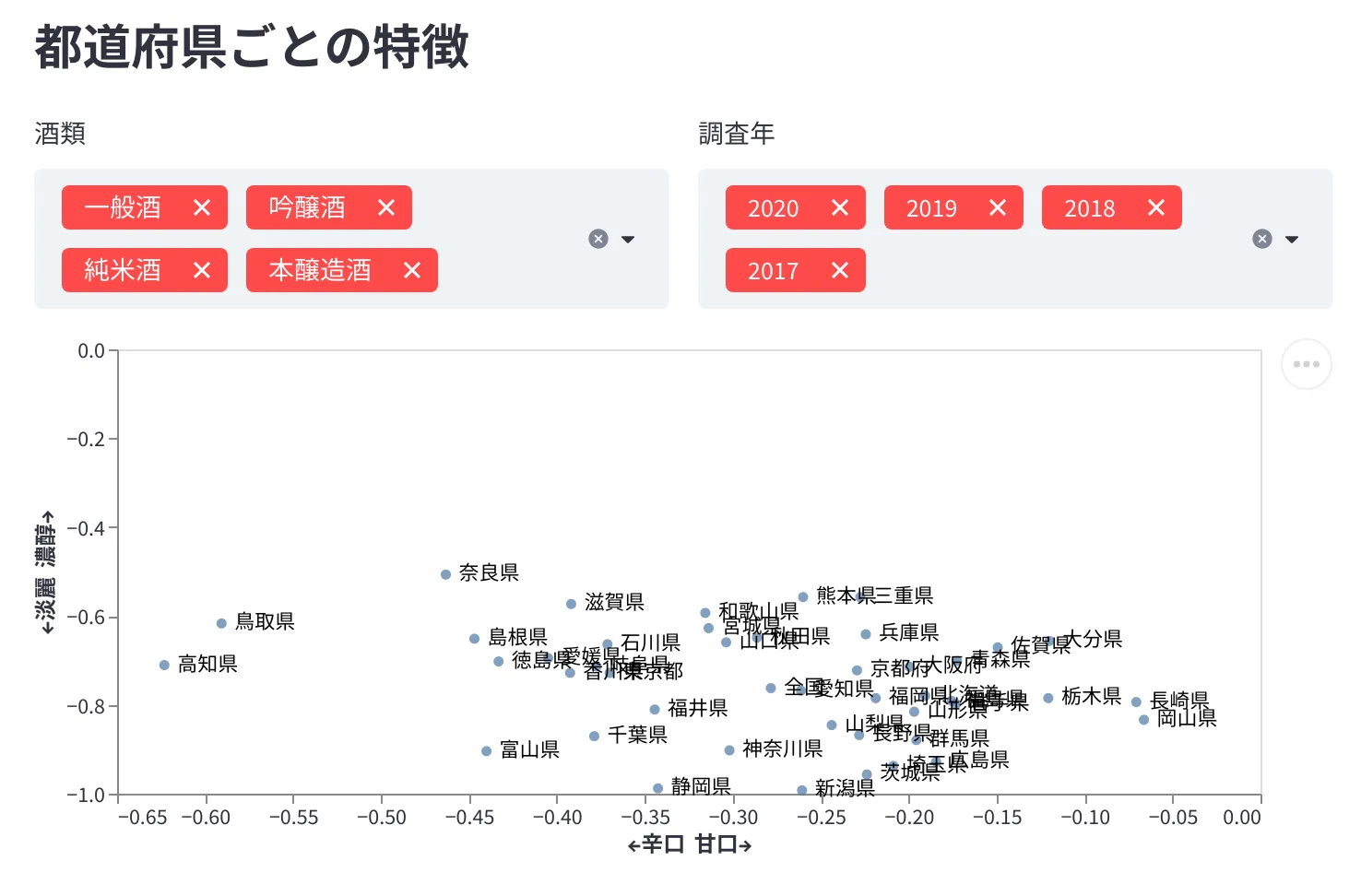
都道府県ごとの特徴
地域で特徴がまとまっているなどはなさそうに見える。地域独特の味の特徴などはないのだろう なんとなく[-0.15, -0.8]あたりの密集地帯に米どころが集まっている
地図上にプロットすると、割と地域の特徴が見える 関西辺りは辛口気味で、他は普通ー甘口。九州甘い
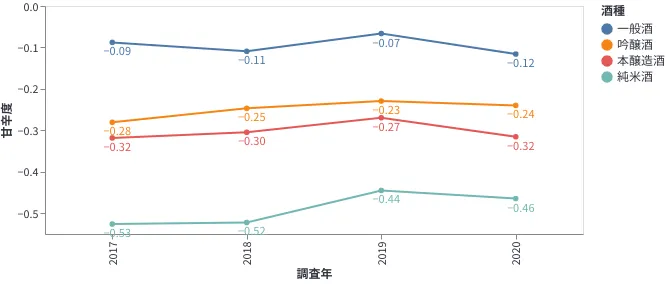
日本酒度の経年変化
日本酒度は、清酒の比重を表している。日本酒度は比重と半比例の関係にある。主に混ざるものとしては糖分(多いほど-に)とアルコール(多いほど+に)がある 本醸造酒は醸造アルコールを添加しているのでやや日本酒度が高くなっている
傾向を見ると甘口・辛口でも無い方向に収束していってるように見える
参考
日本酒の成分に関する用語が結構特殊であるが、日本酒界隈ではおそらく一般的なのであろう