ginzaとnetworkxを用いて共起語ネットワークを描画する関数を作った。せっかくなので残しておく
Rだと割と簡単に作成できるがpythonだとよさげなライブラリが見つからず、なかなか難しかった
*こちらのコードは、分析を担当した現代短歌のテキストマイニング―𠮷田恭大『光と私語』を題材ににて使用したものです。解析結果が載っている箇所はこちら
環境
- python: 3.6
- ginza: 2.2.0
- networkx: 2.4
関数
エッジの太さは共起した回数で表現した。また品詞ごとにノードを色分けして描画するようにした。
共起関係をdataframeにする
import pandas as pd
import collections
import itertools
from scipy import sparse
import math
def get_co_df(doc):
"""
ginzaのdocを受け取って、1文ごとに共起語の組み合わせをカウントする
"""
sentences = list(doc.sents)
# 各文の2-gramの組み合わせ
sentence_combinations = [list(itertools.combinations(sentence, 2)) for sentence in sentences]
# listをflatにする
tc = []
for sentence in sentence_combinations:
tc.extend(sentence)
# (word, pos)の組み合わせで共起語をカウント
tc_set = [((t[0].text, t[0].pos_), (t[1].text, t[1].pos_)) for t in tc]
# 出現回数
ct = collections.Counter(tc_set)
#ct.most_common()[:10]
# sparce matrix
# {単語, インデックス}の辞書作成
tc_set_0 = [(t[0].text, t[0].pos_) for t in tc]
tc_set_1 = [(t[1].text, t[1].pos_) for t in tc]
ct_0 = collections.Counter(tc_set_0)
ct_1 = collections.Counter(tc_set_1)
dict_index_ct_0 = collections.OrderedDict((key[0], i) for i, key in enumerate(ct_0.keys()))
dict_index_ct_1 = collections.OrderedDict((key[0], i) for i, key in enumerate(ct_1.keys()))
dict_index_ct = collections.OrderedDict((key[0], i) for i, key in enumerate(ct.keys()))
#print(dict_index_ct_0)
# 単語の組合せと出現回数のデータフレームを作る
word_combines = []
for key, value in ct.items():
word_combines.append([key[0][0], key[1][1], value, key[0][1], key[1][1]])
df = pd.DataFrame([{
'word1' : i[0][0][0], 'word2' : i[0][1][0], 'count': i[1]
, 'word1_pos': i[0][0][1], 'word2_pos':i[0][1][1]
} for i in ct.most_common()])
return df描画用
import networkx as nx
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
def get_cmap(df: pd.DataFrame):
"""
Args:
df(dataframe): 'word1', 'word2', 'count', 'word1_pos', 'word2_pos'
Returns:
{'ADP': 1, ...}
"""
# 単語のposを抽出 indexで結合
df_word_pos = pd.merge(pd.melt(df, id_vars=[], value_vars=['word1', 'word2'], value_name='word')
, pd.melt(df, id_vars=[], value_vars=['word1_pos', 'word2_pos'], value_name='pos')
, right_index=True, left_index=True).drop_duplicates(subset=['word', 'pos'])[['word', 'pos']]
# posごとに色を付けたい
cmap = set(df_word_pos['pos'].tolist())
cmap = {k: v for v, k in enumerate(cmap)}
return df_word_pos, cmap
def get_co_word(df: pd.DataFrame, word: str):
"""
Args:
df(pd.DataFrame):
Returns:
df_ex_co_word: 関連する単語のみを抽出する
"""
# 特定のwordのみ抽出
df_word = pd.concat([df[df['word1'] == word], df[df['word2'] == word]])
# 単語のposを抽出 indexで結合
df_word_pos = pd.merge(pd.melt(df_word, id_vars=[], value_vars=['word1', 'word2'], value_name='word')
, pd.melt(df_word, id_vars=[], value_vars=['word1_pos', 'word2_pos'], value_name='pos')
, right_index=True, left_index=True).drop_duplicates(subset=['word', 'pos'])[['word', 'pos']]
# 特定の単語と関連する単語群の繋がり関係のみ抽出
# 関連ワードがword1 or word2にある行を抽出
df_ex_co_word = df[df[['word1', 'word2']].isin(list(df_word_pos['word'])).any(axis=1)]
return df_ex_co_word
def get_network(df, edge_threshold=0):
"""
df
'word1', 'word2', 'count', 'word1_pos', 'word2_pos'
"""
df_net = df.copy()
# networkの定義
nodes = list(set(df_net['word1'].tolist()+df_net['word2'].tolist()))
graph = nx.Graph()
# 頂点の追加
graph.add_nodes_from(nodes)
# 辺の追加
# edge_thresholdで枝の重みの下限を定めている
for i in range(len(df_net)):
row = df_net.iloc[i]
if row['count'] > edge_threshold:
graph.add_edge(row['word1'], row['word2'], weight=row['count'])
# 孤立したnodeを削除
#isolated = [n for n in G.nodes if len([i for i in nx.all_neighbors(G, n)]) == 0]
#graph.remove_nodes_from(isolated)
return graph
def plot_draw_networkx(df, word=None, figsize=(20, 20)):
"""
wordを指定していれば、wordとそれにつながるnodeを描画する
"""
G = get_network(df)
plt.figure(figsize=figsize)
# k = node間反発係数 weightが太いほど近い
pos = nx.spring_layout(G, k=0.5)
pr = nx.pagerank(G)
# nodeの大きさ
# posごとに色を付けたい
df_word_pos, c = get_cmap(df)
cname = ['aquamarine', 'navy', 'tomato', 'yellow', 'yellowgreen'
, 'lightblue', 'limegreen', 'gold'
, 'red', 'lightseagreen', 'lime', 'olive', 'gray'
, 'purple', 'brown' 'pink', 'orange']
# cnameで指定する。品詞と数値の対応から、nodeの単語の色が突合できる
cmap_all = [cname[c.get(df_word_pos[df_word_pos['word'] == node]['pos'].values[0])] for node in G.nodes()]
# 出力する単語とつながりのある単語のみ抽出、描画
words = []
edges = []
if word is not None:
df_word = pd.concat([df[df['word1'] == word], df[df['word2'] == word]])
words = list(pd.merge(pd.melt(df_word, id_vars=[], value_vars=['word1', 'word2'], value_name='word')
, pd.melt(df_word, id_vars=[], value_vars=['word1_pos', 'word2_pos'], value_name='pos')
, right_index=True, left_index=True).drop_duplicates(subset=['word', 'pos'])[['word', 'pos']]['word'])
edges = list(df_word[['word1', 'word2']].apply(tuple, axis=1))
cmap = [cname[c.get(df_word_pos[df_word_pos['word'] == node]['pos'].values[0])] for node in words]
nx.draw_networkx_nodes(G, pos, node_color= cmap if word is not None else cmap_all
, cmap=plt.cm.Reds
, alpha=0.3
, node_size=1000
, nodelist= words if word is not None else G.nodes() # 描画するnode
)
# 日本語ラベル
labels = {}
for w in words:
labels[w] = w
nx.draw_networkx_labels(G, pos
, labels=labels if word is not None else None
, fontsize=14, font_family='IPAexGothic'
, font_weight="bold"
)
# 隣あう単語同士のweight
edge_width = [G[edge[0]][edge[1]]['weight']*1.5 for edge in edges]
nx.draw_networkx_edges(G, pos
, edgelist= edges if word is not None else G.edges()
, alpha=0.5
, edge_color="darkgrey"
, width= edge_width if word is not None else edge_width
)
plt.axis('off')
plt.show()実行用スクリプト
import spacy
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# dataset
df = pd.DataFrame({'文書': [
'吾輩は猫である。名前はまだ無い。'
,'猫ちゃんがいる!可愛いね!'
,'あれは猫ちゃんですか?いいえ、狸です。'
,'猫カフェいきたい。'
,'猫か犬か、それが問題だ。'
,'犬も悪くない。'
]})
# exec spacy
nlp = spacy.load('ja_ginza')
docs = [nlp(s) for s in df['文書']]
# 共起語関係取得
df_word_count = pd.concat([get_co_df(d) for d in docs]).reset_index(drop=True)
# 記号 助詞 接続詞を除外
extract_pos = ['ADP', 'INTJ', 'PUNCT', 'SCONJ']
df_ex_word_count = df_word_count[(~df_word_count['word1_pos'].isin(extract_pos)) \
& (~df_word_count['word2_pos'].isin(extract_pos))]
# 共起回数を全文書でまとめておく
df_net = df_ex_word_count.groupby(['word1', 'word2', 'word1_pos', 'word2_pos']).sum() \
['count'].sort_values(ascending=False).reset_index()
全単語描画する
ginzaのsentence分割は優秀なので!で文章が分けられる模様。可愛い-ねが孤立したネットワークになっている
plot_draw_networkx(df_net)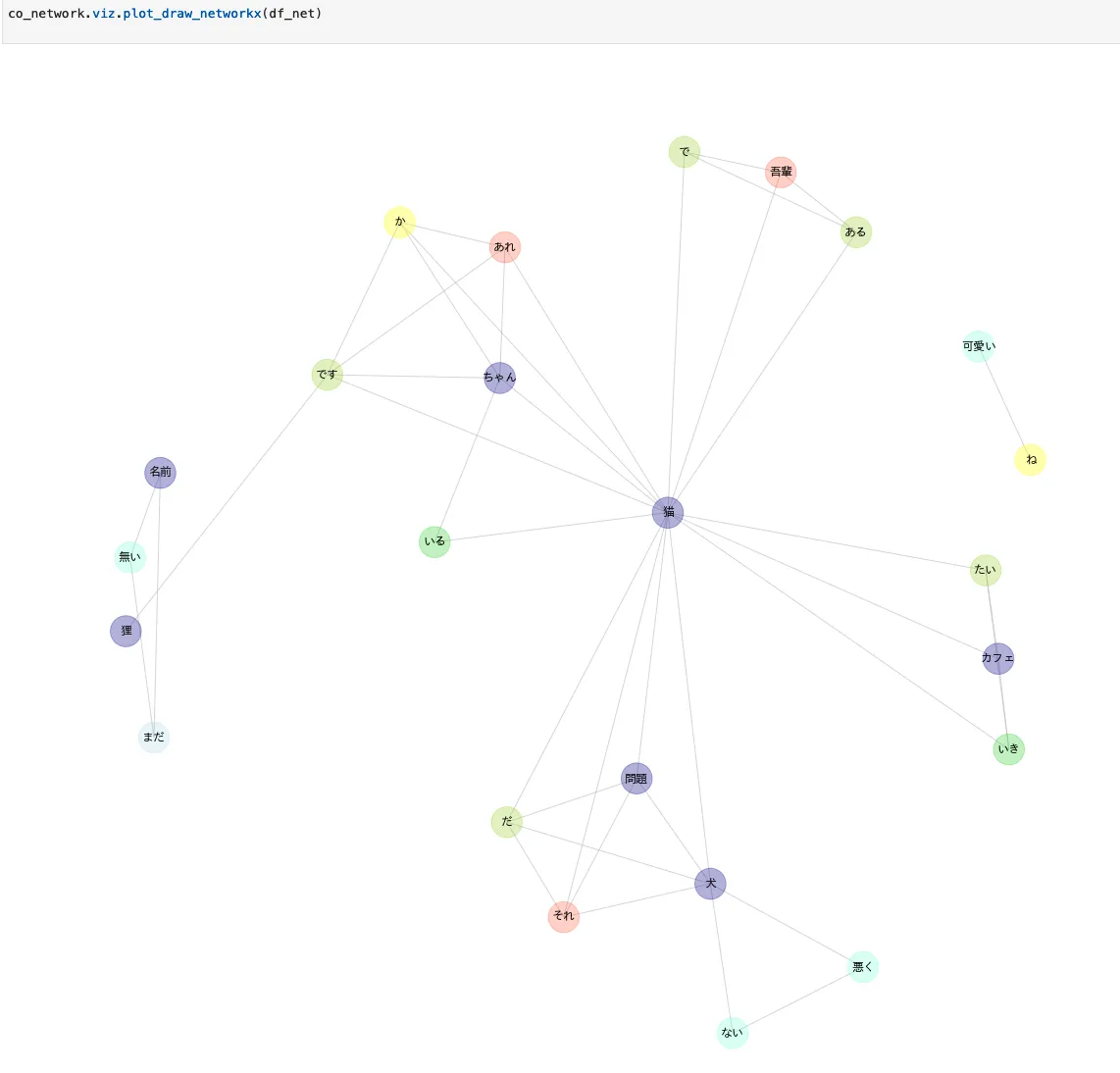
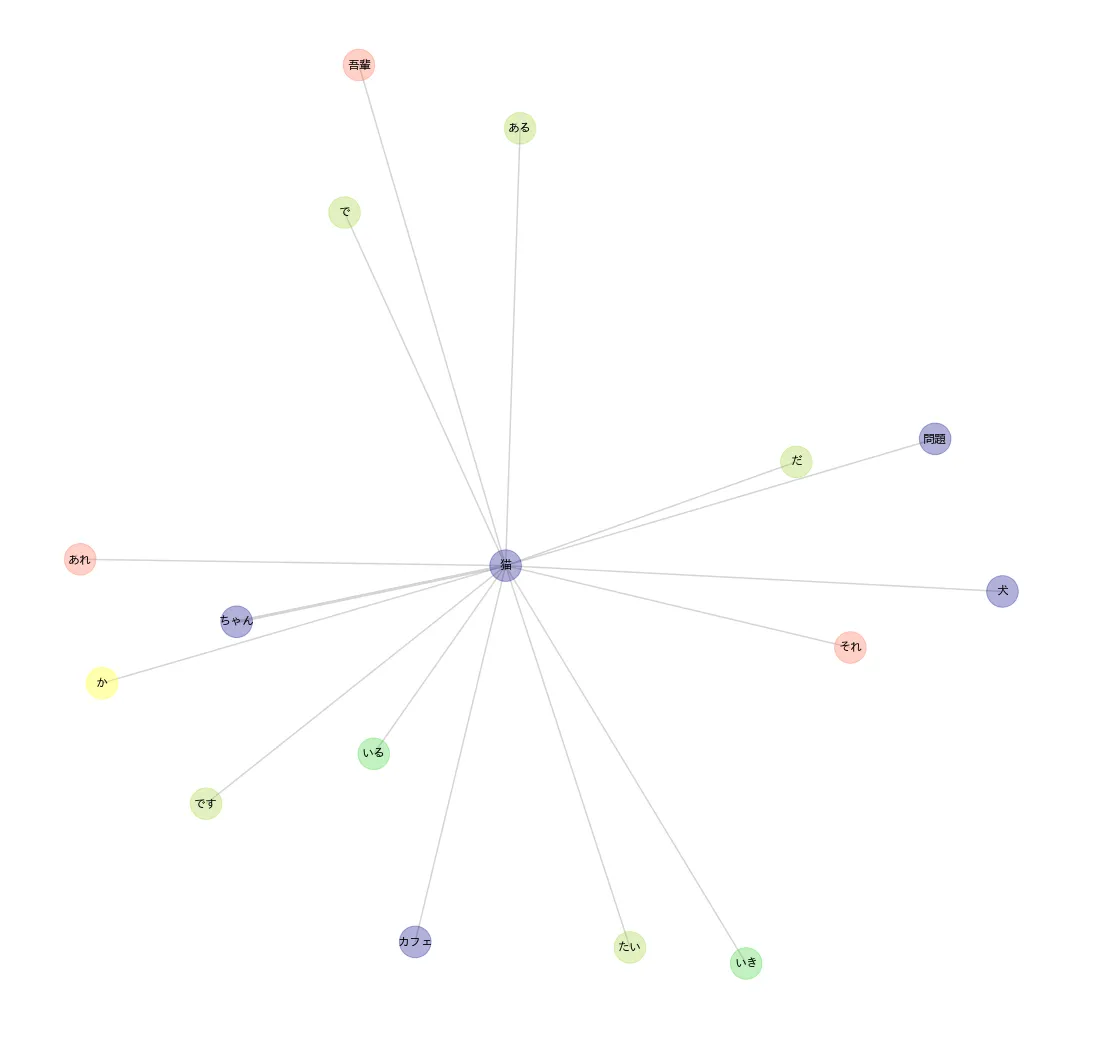
猫を中心に描画する
plot_draw_networkx(df_net, word='猫')