近年、ポケモンも1000種を超えており、データセットとしては豊富になっている。また、poke apiという簡単にデータ取得できる環境も整っているため題材としてやりやすそう、と思いやってみた
ネットワークを描きつつ、主にポケモンのタイプへ着目した描画をおこなった。あわせてネットワーク分析も試みている。
環境
- node: 22.x
- @observablehq/framework: 1.13.3
poke api
apiの使い方などは日本語記事もたくさんあるため割愛。ポケモンの基本的な用語などについても説明は省略する
poke apiの成り立ちや沿革は公式のaboutページに書いてある。完全にオープンコミュニティで作られているものらしい
データセット
今回使用したAPIのエンドポイントはpokemonとpokemon-species。前提として、タイプなどは最新のものを、ポケモンの別フォームなどは集計対象外としている
単位
集計中に調べた内容をメモしておく。pokemonエンドポイントではweightとheightの値を取得できる。数値が大きく感じたため単位を調べたところ、ドキュメントに記載があった。
The height of this Pokémon in decimetres.
The weight of this Pokémon in hectograms.
ref. https://pokeapi.co/docs/v2
hectogramsという単位、しらなかった。1 hectgram = 0.1 kilogramだそう
両方の値を0.1倍すればメートルやキログラム単位へ変換される。INT型で保持し、処理時の桁落ちを防ぐためのお作法だ。
その他
集計に使えそうだが、一般的ではないと考えたデータ。今回は使用していない。将来的に分析する可能性があるためメモしておく。
color
pokemon-speciesにある。ポケモンの色。図鑑でソートするときの色準拠らしい
以下10種類、color urlをたどると日本語名もあった
blue
green
brown
black
purple
pink
yellow
white
red
grayshape
pokemon-speciesにある。ポケモンの形態?図鑑でソートするときの形準拠らしい
以下14種類、こちらは日本語名のデータは無さそうだった
squiggle
bug-wings
upright
quadruped
wings
arms
legs
heads
tentacles
humanoid
ball
fish
armor
blobコード周り(observable framework)
リポジトリはこちら https://github.com/uni-3/observable-framework-dashboard
前提としてプロジェクトのセットアップ済みとする
グラフの描画は基本observable plotか、d3.jsを用いた。カスタムした部分や特筆する部分を書いておく
データセット
色々加工して、最終的に使用したテーブルの中身は以下のような感じ。ポケモンごとに、タイプ、大きさ、世代のレコードを格納したデータセットを作成した
name height weight type_name generation_name
フシギダネ 0.7 6.9 くさ カントー
フシギダネ 0.7 6.9 どく カントー
フシギバナ 2.0 100.0 くさ カントー
フシギバナ 2.0 100.0 どく カントー
オニドリル 1.2 38.0 ノーマル カントーobservable frameworkは基本的にデータローダー経由でテーブルなどのデータを取得する(テーブルとデータローダーファイルは1:1になる)。作成されるデータは、プロジェクト内の src/.observablehq/cache/data 以下に吐き出されるので、ファイルの中身を確認しながらプロット作成を進めた。またデータローダーは標準出力にデータを出力するので、uv run src/data/xx.csv.pyなどと実行することでも確認ができる
ネットワークデータの取得
d3.jsで描画しやすいようにnodes/linksのオブジェクトでデータを作成し、jsonで出力している
今回、タイプの共起グラフと、ポケモン、タイプの二部グラフの2種類のグラフを作成した。
ここで、タイプのノードは同一データを使う。同じjsonファイル内にkey名をtype_nodesやpokemon_nodeと分けて書き出すことで、データロードの重複を防止した。これにより、どちらのグラフ描画でも同一データを用いている。
次数中心性の算出にはdata loader中でnetworkxを用いている。次数中心性などの属性データはoutput用のnodesにいれておき、適宜tooltipなどで使っている
コード抜粋、次数中心性の算出と、outputのイメージ
...
# タイプ別カウントなどの取得
type_stats_query="""
...
"""
...
type_data = {}
...
# 共起リンクの計算
# t1.type_name < t2.type_nameとすることで逆のリンクを重複して計算しないようにする
co_occurrence_query = """
SELECT
t1.type_name AS source,
t2.type_name AS target,
COUNT(*) as value
FROM
pokemon.pokemon_height_weight t1
JOIN
pokemon.spokemon_height_weight t2
ON t1.name = t2.name AND t1.type_name < t2.type_name
GROUP BY 1, 2
"""
# タイプノード
G = nx.Graph()
co_links = []
for row in con.sql(co_occurrence_query).fetchall():
co_links.append({
"source": row[0],
"target": row[1],
"value": row[2]
})
G.add_edge(row[0], row[1], weight=row[2])
# ネットワーク指標の計算 (Centrality)
degree_cent = nx.degree_centrality(G)
# ノードリストの構築 集計値とマージ
nodes = []
for type_name, stats in type_data.items():
nodes.append({
**stats,
"degree_centrality": round(degree_cent.get(type_name, 0), 3),
"group": 1
})
...
# ポケモン、タイプごとの二部グラフのnode linkの取得
co_links = ...
bipartite_links = ...
...
output = {
"type_nodes": nodes,
"pokemon_nodes": pokemon_nodes,
"co_links": co_links,
"bipartite_links": bipartite_links
}
print(json.dumps(output, ensure_ascii=False))ネットワーク図のplot定義。次数中心性として表示する部分を抜粋。グラフのプロットだけで100行くらいのコードになる。AIが一瞬で書いてくれるから楽ではあるが。読むのが大変
// ノード
const node = svg.append("g")
.selectAll("g")
.data(nodes)
.join("g")
.attr("transform", d => `translate(${d.x},${d.y})`)
.attr("cursor", "pointer")
.call(d3.drag()
.on("start", dragstarted)
.on("drag", dragged)
.on("end", dragended));
...
// マウスイベント
node
.on("mouseover", (event, d) => {
tooltip.style("visibility", "visible");
const content = `
<strong>タイプ: ${d.type_name}</strong><br>
合計: ${d.total_count}<br>
単タイプ数: ${d.single_type_count}<br>
単タイプ率: ${(d.single_type_rate * 100).toFixed(1)}%<br>
次数中心性: ${d.degree_centrality.toFixed(3)}
`;
tooltip.html(content);
d3.select(event.currentTarget).select("circle").attr("stroke", "#ccc");
})
.on(
...余談だが、ゴーストはタイプとポケモンの両方に存在する。そのため、二部グラフでノードを同一視する問題が発生した。ワークアラウンドとして描画設定にprefixを付与して対応した。
```js
const bipartite_width = 800;
const bipartite_height = 800;
// データを結合 (タイプノード + ポケモンノード)
const bipartite_nodes = [
...pokemon_network.type_nodes.map(d => ({...d, group: 1, uid: `type:${d.type_name}`})),
...pokemon_network.pokemon_nodes.map(d => ({...d, group: 2, uid: `pokemon:${d.name}`}))
];
const bipartite_links = pokemon_network.bipartite_links.map(d => ({
source: `pokemon:${d.source}`,
target: `type:${d.target}`
}));
...
```フィルタ機能
公式ページにコンポーネントはのっているが、組み合わせが少しむずかしかったためかいておく。グラフに対して世代名で絞り込む機能を例にかいていく
フィルタ機能の定義にviewを使うことで、値を更新した際、その変数を用いている箇所が再計算される。これはreactivityという機能としてドキュメントでも紹介されている。
状態管理のロジックを書かなくても、変数を参照するだけで、自動的にグラフ部分(具体的には```で囲ったブロック)のみ再計算するようになる
実際のコード(マークダウン)は以下
selectedGenerationsで世代名を選択するフィルタ機能を実装し、filtered_count_pokemon_typeでの表示データ絞り込み処理を記述している。
```js
const generationColors = {
"カントー": "#ef5350",
"ジョウト": "#ffa726",
"ホウエン": "#66bb6a",
"シンオウ": "#42a5f5",
"イッシュ": "#78909c",
"カロス": "#ab47bc",
"アローラ": "#ffee58",
"ガラル": "#26a69a",
"パルデア": "#ec407a"
};
// type_name, generation_name, countのデータ
const count_pokemon_type = FileAttachment("../data/pokemon-type.csv").csv({typed: true});
```
## 世代ごとのポケモンタイプ数
```js
const selectedGenerations = view(Inputs.checkbox(Object.keys(generationColors), {
label: "世代で絞る",
value: Object.keys(generationColors)
}));
```
```js
const filtered_count_pokemon_type = count_pokemon_type.filter((d) =>
selectedGenerations.includes(d.generation_name)
);
```
```js
Plot.waffleY(
filtered_count_pokemon_type, {
x: "type_name",
...
})
```
表示はこんな感じになる。UIがちょっとイマイチ
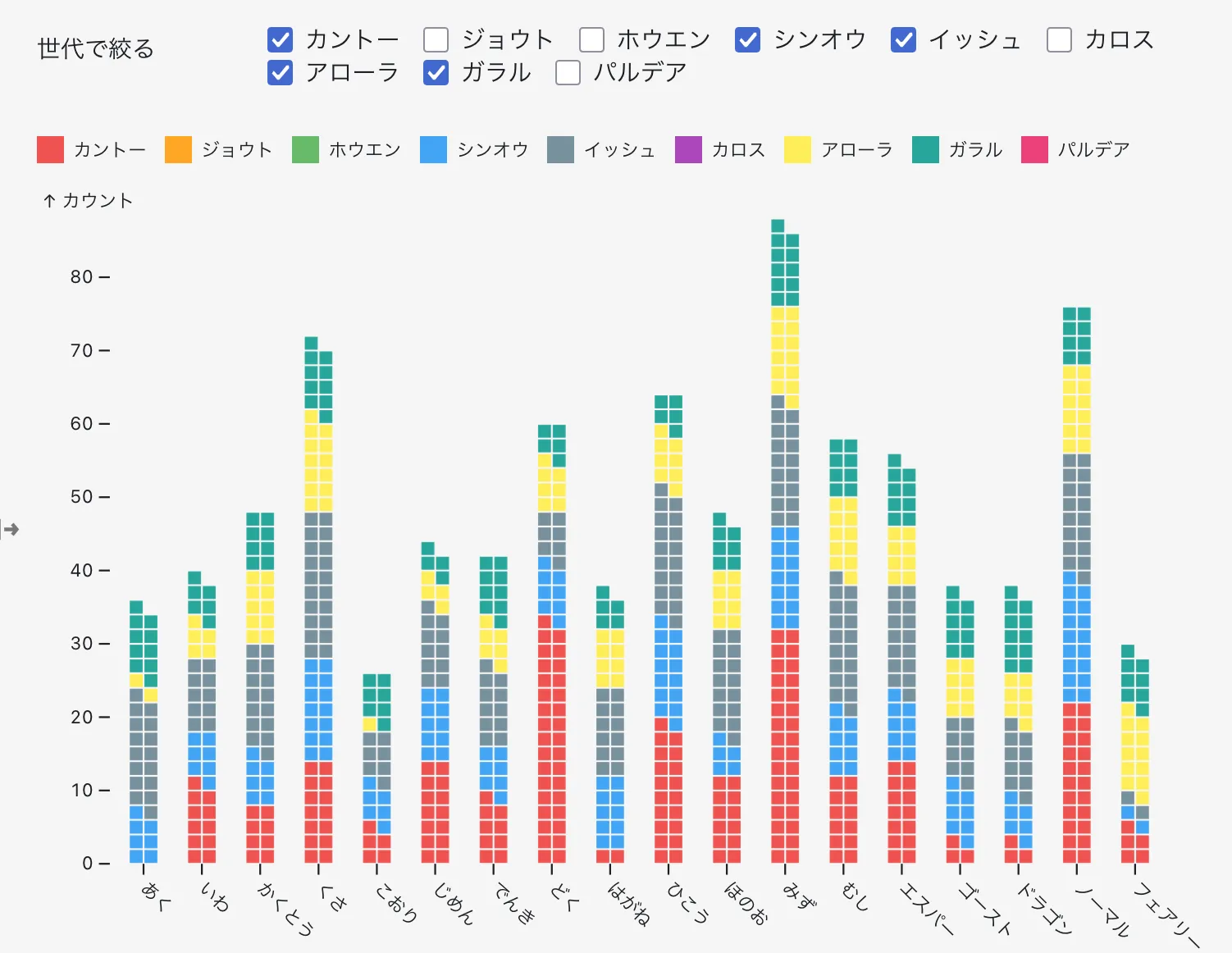
グラフ
データを眺めてみる
タイプと世代
ページはこちら。世代とタイプなどのデータを使って適当にプロットした
https://uni-3.github.io/observable-framework-dashboard/pokemon/analytics
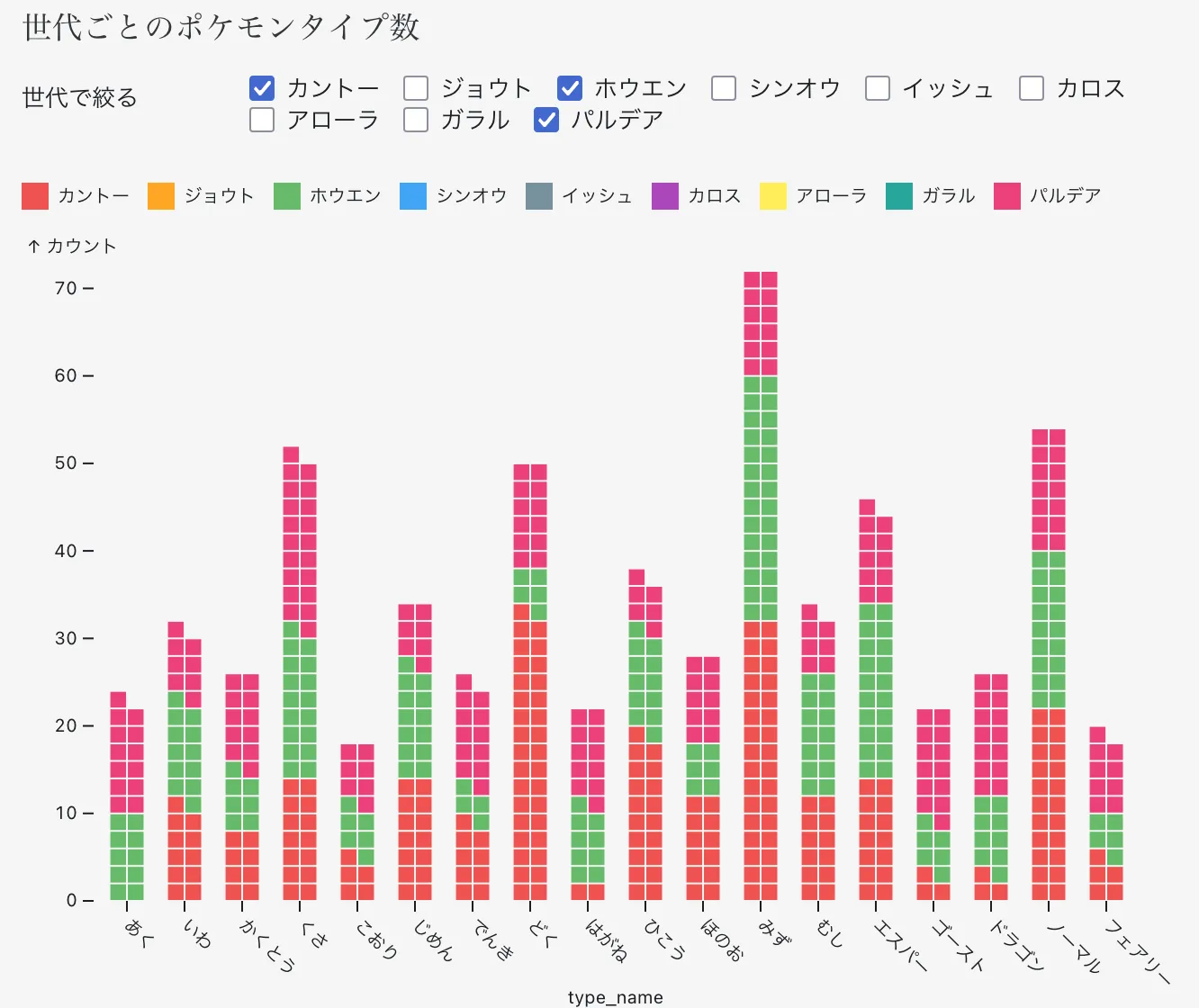
ここでは一部のグラフについて考察する。世代ごとに新規ポケモンのタイプ数をみてみる
分布を見やすくするため世代で色分けした棒グラフを作成した
実数を見やすくするためクロス集計も作成した
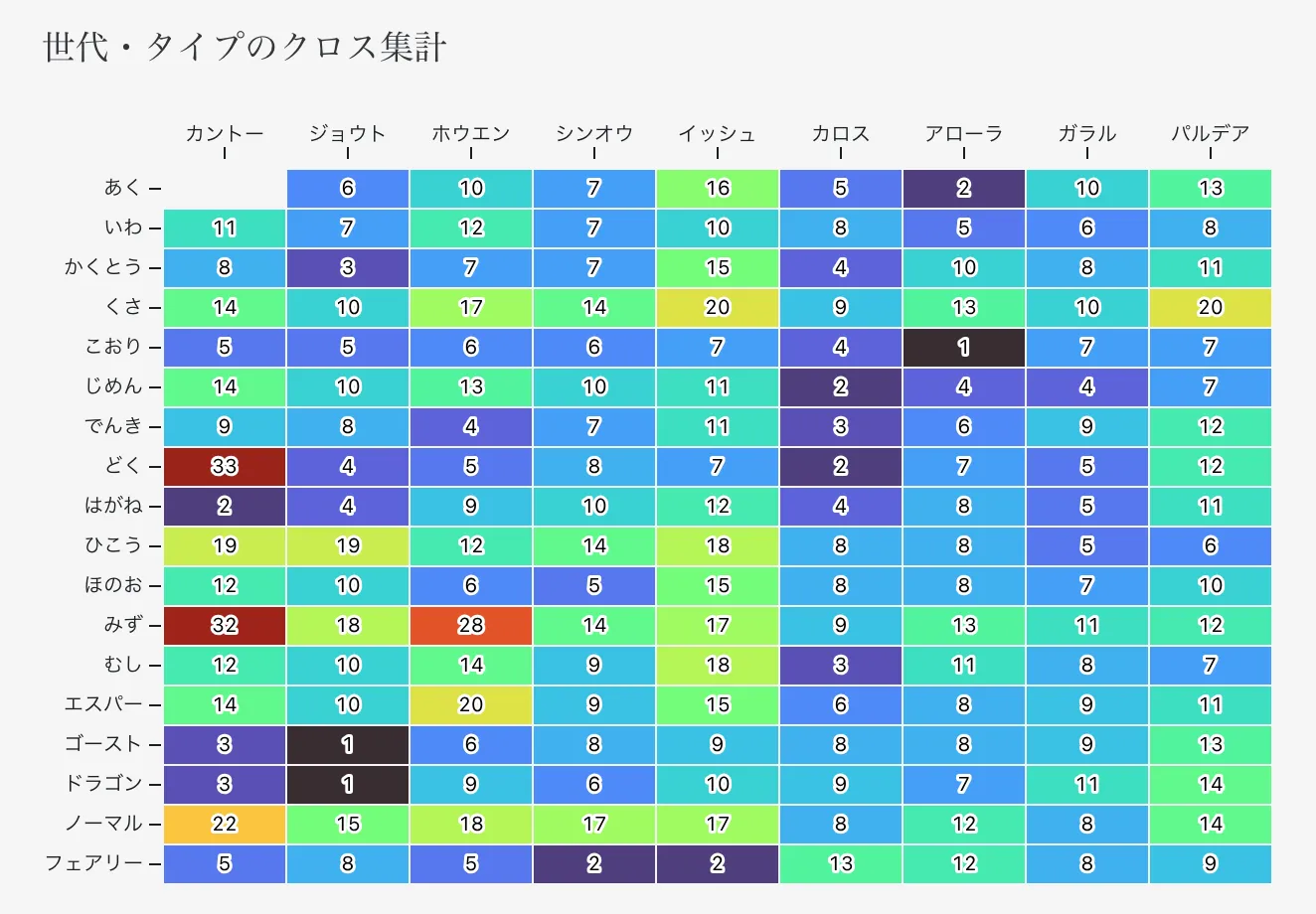
どく、みずは最初の方(カントー、ホウエン)に発見されすぎたのか、最近の世代(カロス以降)において新規数は少なめになっている
反対にゴースト、ドラゴンについてはだんだん増えて、メジャー化していっているみたい
タイプの共起度合い
ページはこちら。タイプとポケモンの関係をネットワーク図で表現した。大きいネットワークでもノード数1000くらいリンク数はその1.5倍の1500くらいだが、割とブラウザも重くならず描画できている。
https://uni-3.github.io/observable-framework-dashboard/pokemon/network
一部の分析について考察していく。ネットワーク分析めいたことをした。ポケモンとそのタイプについてグラフを作成し、複タイプの出現しやすい組み合わせや、単タイプが多いタイプについて確認した。
タイプの共起ネットワーク図。個体数が多いほどノードも大きく、リンクが太いほど、複タイプをもつ個体が多い。ひこうタイプに貼られているリンクは基本多そう。
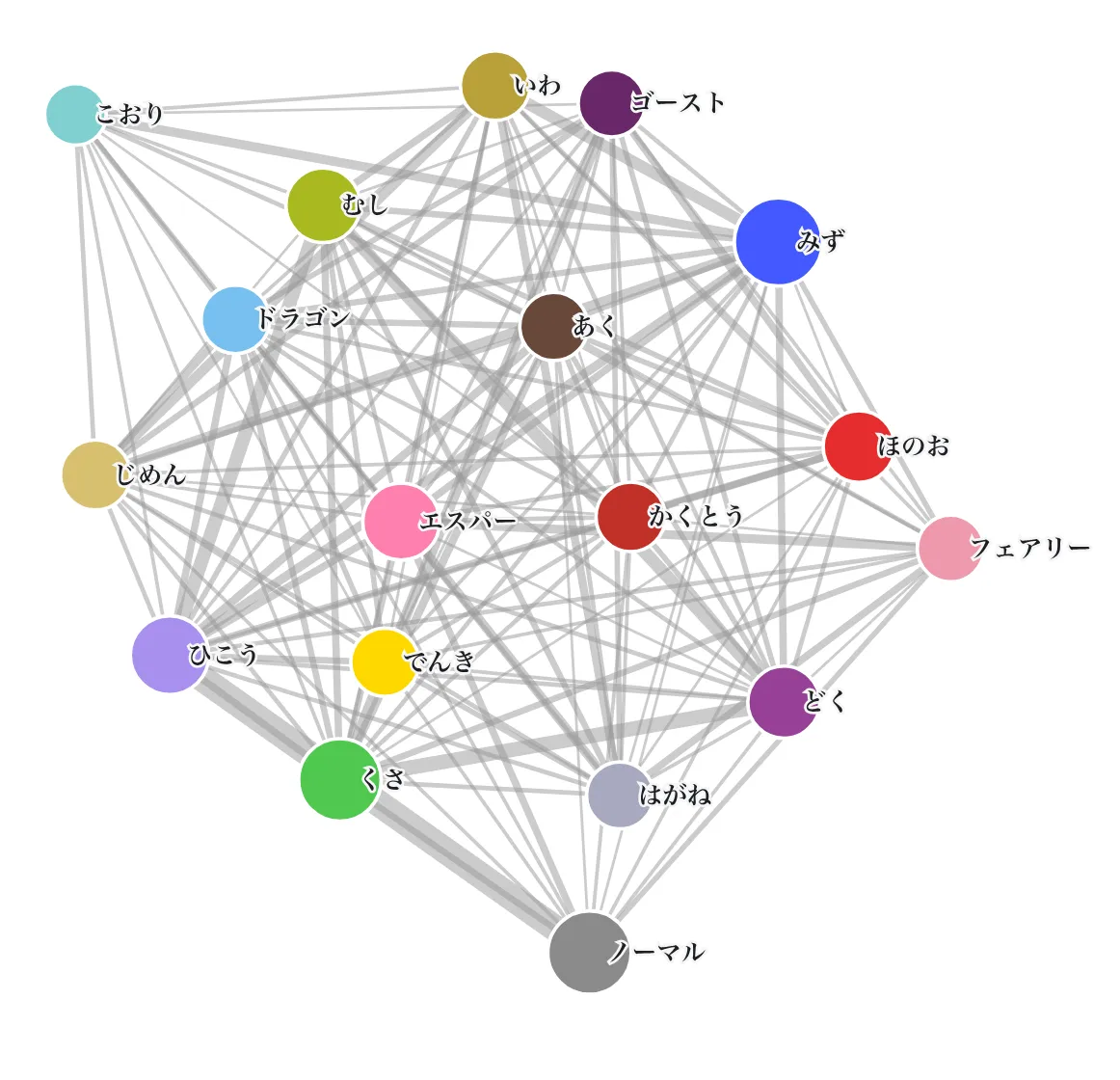
数値で見ると、一番リンクが多かったのはノーマル・ひこうで27だった
また、単タイプ率が高いのはノーマル、でんきタイプで、50%以上なのはこの2つのタイプのみだった。反対に単タイプ率が低いのはひこうタイプで全109匹中、3匹のみ。ページの方に数値も出している、記事中では割愛する
せっかくのネットワークなので次数中心性もだしてみた
次数中心性 (Degree Centrality): ノードが持つエッジ(直接つながっている他のタイプの数) deg(v) を、自分以外の全ノード数 n−1 で割ったもの。ここでは、どれだけ多くの異なるタイプとの組み合わせがあるかを表す。範囲は0〜1で表され、例えば1.0 の場合は自分以外の全タイプ(17種類)との組み合わせが存在することを意味する。
すべてのタイプと組み合わせのある(次数中心性1.0)タイプは、かくとう・あく・ひこう・みずだった。これらは何らかの属性が付与されていても不自然ではないタイプといえる。
次数中心性が一番小さい(それでも0.765で、13タイプとの組み合わせがある)タイプはフェアリー、ノーマル、こおりだった。フェアリーはエスパーと、こおりはみずとの複タイプが比較的多いのでそういった要因もありそう。
関連記事
ポケモンでネットワーク分析、なにか既存のあるかなと思って探した(AIが)
ポケモンや世代などのノードを使って6部グラフ?くらいのネットワークを描画している
ポケモンの相性と能力値を考慮した相性ネットワークなども描いている
今回行った以外にも色々テーマが作れそうなデータセットだった。