fivetran connector sdkを使いestat apiのデータを取得した。sdkの設定からgithub actionsでの手動実行までを試みる。fivetranはデータのloadとdestinationの機能が分離されており、管理しやすいサービスだと感じた。
環境
- fivetran-connector-sdk: 2.1.1
- requests: 2.32.5
デバッグ時に必要
- duckdb: 1.2.1
パッケージのインストールには以下のコマンドを実行
uv add fivetran-connector-sdk requests
uv add --dev duckdb今回はfivetrans_projectフォルダ以下にプロジェクトを構築した。最終的な構造は以下の通りだ。
tree -L 1
.
├── README.md
├── configuration.example.json
├── configuration.json
├── connector.py
├── pyproject.toml
├── requirements.txt
└── uv.lockまた、fivetranのアカウント作成は済ませているものとする
fivetran connector SDK
公式ブログの日付によれば、2025年6月にGAとなったようだ。
https://www.fivetran.com/blog/fivetran-connector-sdk-unlocking-every-data-source
それ以前はAWS Lambdaなどのサーバーレスコンピューティング関数を実行する機能が提供されていた。function connectionsという名称だったが、現在は新規作成できない。
https://fivetran.com/docs/connectors/functions
実装
実行コード
実行ファイルはconnector.pyという名称で作成する。
ここではestat apiから特定のデータセット、ここでは年齢(5歳階級)・男女・月別人口・総人口のデータセットを対象とする。取得されるデータ構造の詳細については割愛する
JSONのパースや型変換はsqlでやればいいので適当な粒度(カテゴリ名テーブルと値テーブル)でとにかく格納しておく
# connector.py
import requests
from fivetran_connector_sdk import Connector, Operations as op
# e-Stat APIのベースURL
ESTAT_API_BASE_URL = "https://api.e-stat.go.jp/rest/3.0/app/json/getStatsData"
# 人口推計の統計表ID
# 統計表名: 年齢(5歳階級),男女,月別人口-総人口(各月1日現在)
# 基準: 令和2年国勢調査基準
# 粒度: 月次 × 年齢5歳階級 × 男女別
# 出典: https://www.e-stat.go.jp/dbview?sid=0003443840
POPULATION_STATS_DATA_ID = "0003443840"
def schema(configuration: dict) -> list[dict]:
"""
テーブルのスキーマを定義
e-Statのデータ構造に基づいて
category(マスタ)とvalue(値)のテーブルを作成
"""
return [
{
"table": "estat_population_category",
"primary_key": ["id"],
"columns": {
"id": "STRING",
"name": "STRING",
# CLASS_OBJ
"class": "JSON"
},
},
{
"table": "estat_population_value",
"primary_key": ["tab", "cat01", "cat02", "cat03", "cat04", "area", "time"],
"columns": {
"tab": "STRING",
"cat01": "STRING",
"cat02": "STRING",
"cat03": "STRING",
"cat04": "STRING",
"area": "STRING",
"time": "STRING",
"unit": "STRING",
"value": "STRING",
},
},
]
def update(configuration: dict, state: dict) -> None:
"""
main関数
"""
# 設定から e-Stat の API キーを取得
app_id = configuration.get("app_id")
if not app_id:
raise ValueError("app_id is required in configuration")
# req params
params = {
"appId": app_id,
"lang": "J",
"statsDataId": POPULATION_STATS_DATA_ID,
"replaceSpChars": "0",
"metaGetFlg": "Y",
"cntGetFlg": "N",
"explanationGetFlg": "Y",
"annotationGetFlg": "Y",
"sectionHeaderFlg": "1",
}
# req estat API
response = requests.get(ESTAT_API_BASE_URL, params=params, timeout=60)
response.raise_for_status()
response_json = response.json()
# 取得したいデータ構造について検証
if "GET_STATS_DATA" not in response_json:
raise Exception(f"Unexpected API response: GET_STATS_DATA not found")
if "STATISTICAL_DATA" not in response_json["GET_STATS_DATA"]:
result = response_json.get("GET_STATS_DATA", {}).get("RESULT", {})
raise Exception(f"Unexpected API response structure: {result}")
statistical_data = response_json["GET_STATS_DATA"]["STATISTICAL_DATA"]
# print("data", statistical_data)
# カテゴリデータ
category_data = parse_category_data(statistical_data)
for row in category_data:
op.upsert("estat_population_category", row)
# 値データ
value_data = parse_value_data(statistical_data)
for row in value_data:
op.upsert("estat_population_value", row)
# チェックポイントを保存
op.checkpoint(state)
def parse_category_data(statistical_data: dict) -> list[dict]:
"""
CLASS_INF.CLASS_OBJ からカテゴリ情報を抽出
"""
rows = []
try:
class_obj = statistical_data.get("CLASS_INF", {}).get("CLASS_OBJ", [])
for idx, item in enumerate(class_obj):
row = {
"id": item.get("@id", str(idx)),
"name": item.get("@name", ""),
"class": item.get("CLASS", "")
}
rows.append(row)
except (KeyError, TypeError) as e:
print(f"Warning: Error parsing category data: {e}")
return rows
def parse_value_data(statistical_data: dict) -> list[dict]:
"""
DATA_INF.VALUE からデータを抽出
"""
rows = []
try:
values = statistical_data.get("DATA_INF", {}).get("VALUE", [])
for item in values:
row = {
"tab": item.get("@tab", ""),
"cat01": item.get("@cat01", ""),
"cat02": item.get("@cat02", ""),
"cat03": item.get("@cat03", ""),
"cat04": item.get("@cat04", ""),
"area": item.get("@area", ""),
"time": item.get("@time", ""),
"unit": item.get("@unit", ""),
"value": item.get("$", ""),
}
rows.append(row)
except (KeyError, TypeError) as e:
print(f"Warning: Error parsing value data: {e}")
return rows
connector = Connector(update=update, schema=schema)
if __name__ == "__main__":
connector.debug()格納部分はop.upsert()とあるとおり、差分のデータのみinsertされる(fivetranは月のデータ転送量で課金するのでusage消費を節約できる)
残りの部分はリクエスト〜パース、スキーマ定義をかいている
stateの細かい挙動までは追っていないが、op.checkpoint(state)としておくと、fivetranのほうでデータの状態を管理するらしい
- 設定ファイル
estat apiへのリクエストには認証用にappIdが必要になる。外部から参照できるようにしたいのでconfiguration.json に設定しておく(秘匿情報なので.gitignoreに追加するのも忘れずに)。設定ファイルの中身は以下の感じ
{
"app_id": "xxxxxxxx"
}
コード中ではこちらの処理にて取得している
app_id = configuration.get(“app_id”)
appIdは、estat apiの画面からユーザー登録とアプリケーションID発行を済ませて取得する。
https://www.e-stat.go.jp/api/api-dev/how_to_use
ローカル実行
fivetran debugコマンドにて動作確認を行う。ローカルでfivetranエミュレーターが起動し、実行される。転送するデータはduckdb(ローカルファイル上)にデータが作成される。データを眺めたり、簡単にjoinとか加工もできるのでガチ便利
- debug実行
コマンドはこちら
fivetran debug --configuration configuration.json
ちなみに、コード中ではmain関数にてデバッグ実行されるよう定義してある
if __name__ == "__main__":
connector.debug()実行ログ
fivetran debug --configuration configuration.json
Dec 16, 2025 05:33:42 PM WARNING: Fivetran-Connector-SDK: `requirements.txt` file not found in your project folder.
Dec 16, 2025 05:33:42 PM INFO: Fivetran-Connector-SDK: Debugging connector at: fivetrans_project
Dec 16, 2025 05:33:42 PM INFO: Fivetran-Connector-SDK: Running connector tester...
...
Dec 16, 2025 05:33:46 PM INFO: Fivetran-Connector-SDK: Initiating the 'schema' method call...
Dec 16, 2025 05:33:46 PM INFO: Fivetran-Tester-Process: [SchemaChange]: tester.estat_population_category
Dec 16, 2025 05:33:46 PM INFO: Fivetran-Tester-Process: [CreateTable]: tester.estat_population_category
Dec 16, 2025 05:33:46 PM INFO: Fivetran-Tester-Process: [SchemaChange]: tester.estat_population_value
Dec 16, 2025 05:33:46 PM INFO: Fivetran-Tester-Process: [CreateTable]: tester.estat_population_value
Dec 16, 2025 05:33:46 PM INFO: Fivetran-Connector-SDK: Initiating the 'update' method call...
Dec 16, 2025 05:35:26 PM INFO: Fivetran-Tester-Process: Checkpoint: {}
Dec 16, 2025 05:35:26 PM INFO: Fivetran-Tester-Process: SYNC PROGRESS:
Operation | Calls
----------------+------------
Upserts | 9889
Updates | 0
Deletes | 0
Truncates | 0
SchemaChanges | 2
Checkpoints | 1
Note: Fivetran debug's performance is limited by your local machine's resources. Your connector will run faster in production.
read about production system resources at https://fivetran.com/docs/connector-sdk/working-with-connector-sdk#systemresources
Dec 16, 2025 05:35:26 PM INFO: Fivetran-Tester-Process: Sync SUCCEEDEDデータ確認
duckdb uiでデータを眺めてみる。データは connector.pyと同じディレクトリ上に files/warehouse.db として作成される
uiサーバーを立ち上げて確認してみる
duckdb -ui files/warehouse.db
...
┌──────────────────────────────────────┐
│ result │
│ varchar │
├──────────────────────────────────────┤
│ UI started at http://localhost:4213/ │
└──────────────────────────────────────┘
v1.2.1 8e52ec4395
Enter ".help" for usage hints.http://localhost:4213/にアクセスしてサイドバーから適当にたどると、tester database以下にテーブルが作成されているのを確認できる
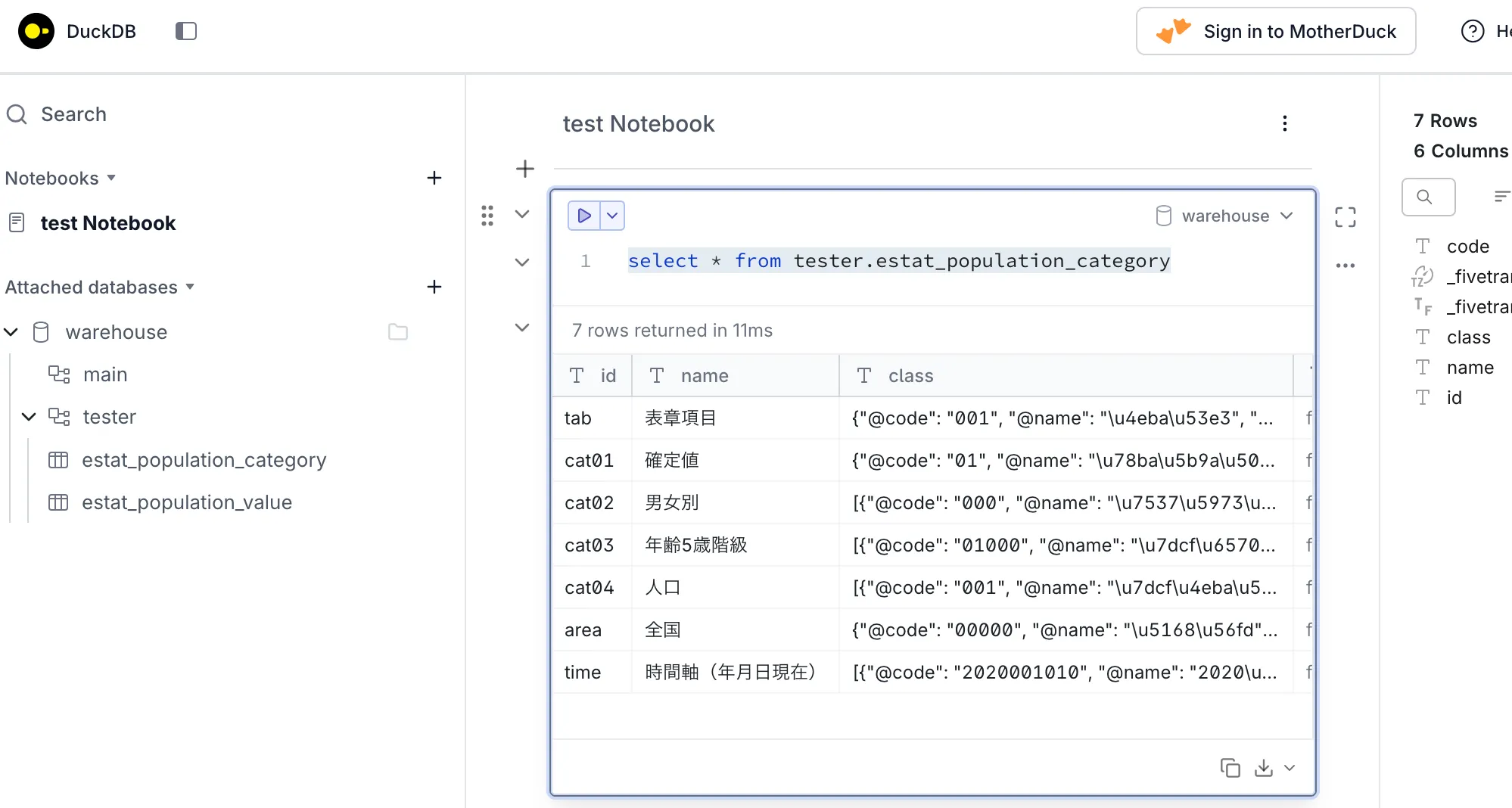
また、画面のメイン部分で開いているnotebookから、クエリの実行が可能
データ変換
記事の本題ではないが、debug上のデータで簡単に変換をしてみる。本来はfivetranのdestination上でやるのが、色々仕様を調べるの大変なので作業メモがてら載せておく
- クエリ最終系
with m as (
SELECT
id,
-- extract from json
obj->>'@code' as code,
obj->>'@name' as name,
obj->>'@level' as level,
obj->>'@unit' as unit
FROM (
SELECT
id,
unnest(from_json(
CASE
-- すでに配列なら何もしない
WHEN json_type(class) = 'ARRAY' THEN class
-- 配列じゃない({}のとき)[] で囲んで配列の形にする
ELSE '[' || CAST(class AS VARCHAR) || ']'
END,
-- JSONが入ったリストとして扱う
'["json"]'
)) as obj
FROM tester.estat_population_category
)
)
SELECT
v.tab,
m_tab.name as tab_name,
v.cat_01,
m_cat01.name as cat01_name,
v.cat_02,
m_cat02.name as cat02_name,
v.cat_03,
m_cat03.name as cat03_name,
v.cat_04,
m_cat04.name as cat04_name,
v.area,
m_area.name as cat04_area,
v.time,
m_time.name as cat04_time,
v.unit,
v.value,
CAST(v.value AS BIGINT) * 1000 as population_value,
FROM tester.estat_population_value v
-- m テーブルの各々のコード部分でjoin nameとりだす
LEFT JOIN m as m_tab
ON m_tab.id = 'tab'
AND m_tab.code = v.tab
LEFT JOIN m as m_cat01
ON m_cat01.id = 'cat01'
AND m_cat01.code = v.cat_01
LEFT JOIN m as m_cat02
ON m_cat01.id = 'cat02'
AND m_cat02.code = v.cat_02
LEFT JOIN m as m_cat03
ON m_cat03.id = 'cat03'
AND m_cat03.code = v.cat_03
LEFT JOIN m as m_cat04
ON m_cat04.id = 'cat04'
AND m_cat04.code = v.cat_04
LEFT JOIN m as m_area
ON m_area.id = 'area'
AND m_area.code = v.area
LEFT JOIN m as m_time
ON m_time.id = 'time'
AND m_time.code = v.time
;こんな感じの結果になる。cat01とスキーマ定義したのにvalueのテーブルのカラム名がcat_01などとなるのが謎。
tab tab_name cat_01 cat01_name cat_02 cat02_name cat_03 cat03_name cat_04 cat04_name area cat04_area time cat04_time unit value population_value
001 人口 01 確定値 000 01000 総数 001 総人口 00000 全国 2020001010 2020年10月 千人 126146 126146000
001 人口 01 確定値 000 01000 総数 001 総人口 00000 全国 2020001111 2020年11月 千人 126106 126106000
001 人口 01 確定値 000 01000 総数 001 総人口 00000 全国 2020001212 2020年12月 千人 126088 126088000
001 人口 01 確定値 000 01000 総数 001 総人口 00000 全国 2021000101 2021年1月 千人 126068 126068000
001 人口 01 確定値 000 01000 総数 001 総人口 00000 全国 2021000202 2021年2月 千人 125990 125990000時間軸コード(timeカラム)
timeカラム、2020年10月 などといった表記で統合できるが、date型にパースしたい
select strptime('2020年10月', '%Y年%m月')::DATE でも行けるようだけど、どうせなら時間軸コードが格納されているtime列のコードに対して適用したい
サイトみても載ってなくて、AIに調べてもらった結果
https://www.e-stat.go.jp/estat/html/machine-readable-stats-format.pdf
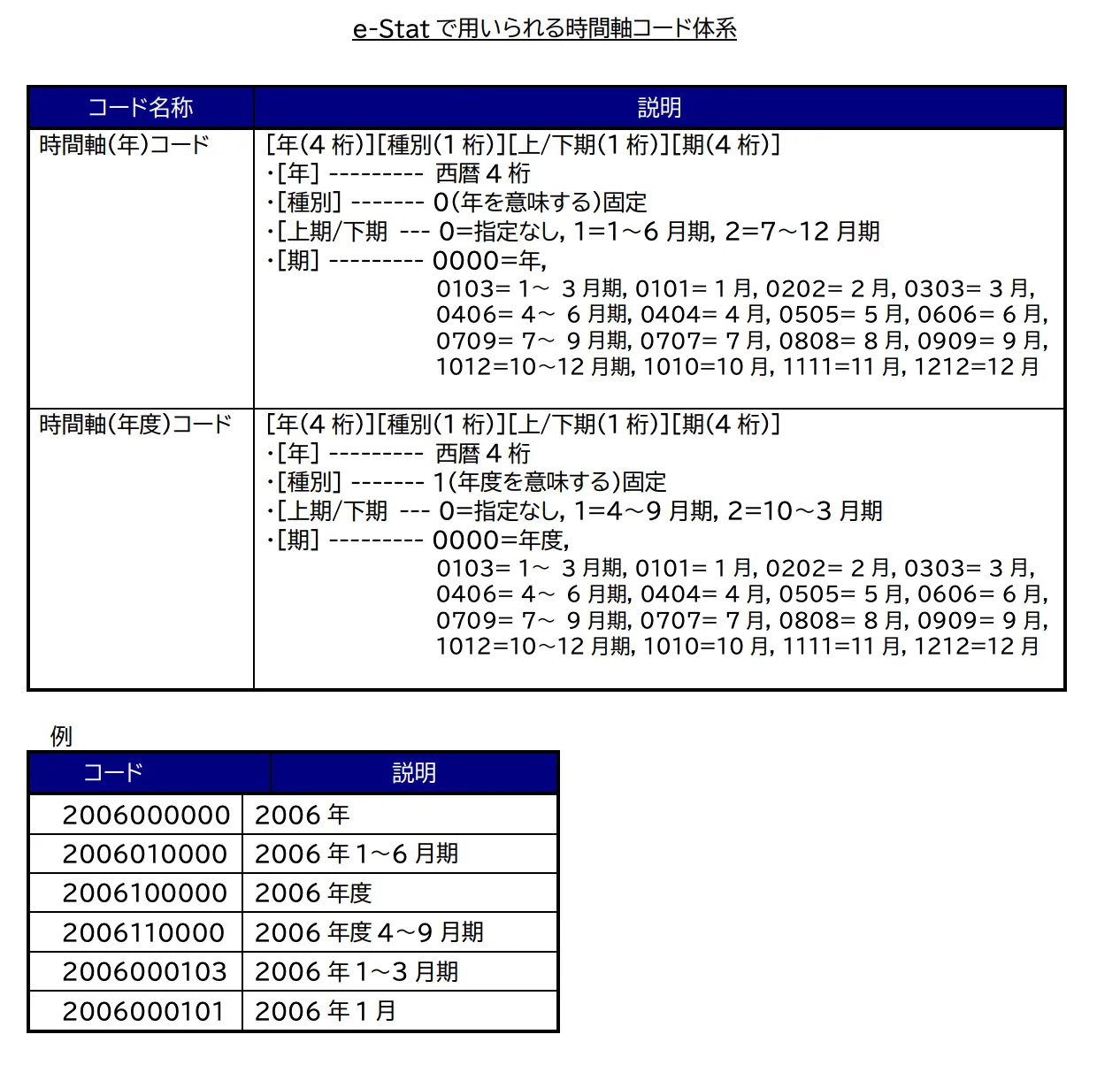
年度、上期・下期表記にも対応している表記とのこと。こういった定義はpdfファイルにまとめてあるよう。estatむずい
デプロイ
connection(取得、転送の実行定義)の作成から実行まで
実行はfivetran環境下で行われる。コンピューティングリソースなどのリミットの記載は特に見つからなかった。今回(10000行くらい)のは1 minもかからず処理が行われた
実行時にはAPIキーとシークレットなどが必要。ログインして、以下ユーザーのAPI keyページから作成
https://fivetran.com/dashboard/user/api-config
destinationもあらかじめ用意する必要がある。今回はbigqueryを使った。ドキュメントに詳しい手順が載っているので割愛する
https://fivetran.com/docs/destinations/bigquery/setup-guide
cli経由
connectionの作成
base64エンコードしたものを使ってねっていわれた
fivetran deploy --api-key X....== --destination motherduck --connection load_estat \
--configuration configuration.json --force
...
Dec 16, 2025 06:48:33 PM INFO: Fivetran-Connector-SDK: Skipping requirements.txt validation as --force flag is set. Ensure that your code is structured accordingly and all dependencies are listed in `requirements.txt`
Dec 16, 2025 06:48:35 PM SEVERE: Fivetran-Connector-SDK: The request failed with status code: 401. Ensure you're using a valid base64-encoded API key and try again.
こちらは、ドキュメントにもあるが、"<API Key>:<Secret Key>" をbase64変換したものを設定する。この値はapi key発行時にも取得可能
https://fivetran.com/docs/rest-api/getting-started#useapikeyinrequests
base64変換したものをセットしたら、作成できた
fivetran deploy --api-key W.....== --destination motherduck --connection load_estat \
--configuration configuration.json --force
Dec 16, 2025 06:53:23 PM INFO: Fivetran-Connector-SDK: Deploying with parameters: Fivetran deploy --destination motherduck --connection load_estati --api-key Wxxxxx --configuration configuration.json --force
Dec 16, 2025 06:53:23 PM INFO: Fivetran-Connector-SDK: We support only `.py` files and a `requirements.txt` file as part of the code upload. *No other code files* are supported or uploaded during the deployment process. Ensure that your code is structured accordingly and all dependencies are listed in `requirements.txt`
Dec 16, 2025 06:53:23 PM INFO: Fivetran-Connector-SDK: Skipping requirements.txt validation as --force flag is set. Ensure that your code is structured accordingly and all dependencies are listed in `requirements.txt`
Dec 16, 2025 06:53:25 PM INFO: Fivetran-Connector-SDK: Deploying 'fivetrans_project' to connection 'load_estat' in destination 'motherduck'.
Dec 16, 2025 06:53:25 PM INFO: Fivetran-Connector-SDK: Packaging your project for upload...
✓
Dec 16, 2025 06:53:25 PM INFO: Fivetran-Connector-SDK: Uploading your project...
✓
Dec 16, 2025 06:53:28 PM INFO: Fivetran-Connector-SDK: The connection 'load_estat' has been created successfully.
Dec 16, 2025 06:53:28 PM INFO: Fivetran-Connector-SDK: Python version 3.14 to be used at runtime.
Dec 16, 2025 06:53:28 PM INFO: Fivetran-Connector-SDK: Connection ID: xxxxxx_xxxxx
Dec 16, 2025 06:53:28 PM INFO: Fivetran-Connector-SDK: Visit the Fivetran dashboard to start the initial sync: https://fivetran.com/dashboard/connectors/dollop_overrule/statusログにある Connection IDは実行時に使うのでとっておく。忘れた場合は、コンソール画面のconnection詳細URL https://fivetran.com/dashboard/connections/xxxx_xxxx のパス末尾、もしくはsetupタブのConnection metadata & setup セクションから確認できる
また、connection名がdestinationでのスキーマ名となる
実行
アドホック実行してみた。前提として、作成されたコネクションは停止状態(pause)になっている。有効(enable)にしてから実行(sync)する必要がある。また、有効にすると、スケジューリング実行も有効になる(最長頻度は1日)
実行して、その後のスケジュール実行は無効にしたい場合、connectionをenable→sync→pauseという手順でいけそうだった(いいのかな?)
実行はAPI経由。簡単にcurlで行う。以下のようなコマンドを実行した
export FIVETRAN_API_KEY_BASE64=W.......
export FIVETRAN_CONNECTION_ID=xxx_xxx
# enable
curl -f -X PATCH "https://api.fivetran.com/v1/connectors/$FIVETRAN_CONNECTION_ID" \
-H "Authorization: Basic $FIVETRAN_API_KEY_BASE64"
-H "Content-Type: application/json" \
-d '{ "paused": false }'
# sync
curl -f -X POST https://api.fivetran.com/v1/connectors/$FIVETRAN_CONNECTION_ID/force \
-H "Authorization: Basic $FIVETRAN_API_KEY_BASE64"
-H "Content-Type: application/json"
# disable
curl -f -X PATCH "https://api.fivetran.com/v1/connectors/$FIVETRAN_CONNECTION_ID" \
-H "Authorization: Basic $FIVETRAN_API_KEY_BASE64"
-H "Content-Type: application/json" \
-d '{ "paused": true }'実行確認。connectionのstatus画面、イベントログ部分にsuccessfull syncとあるので動かせている
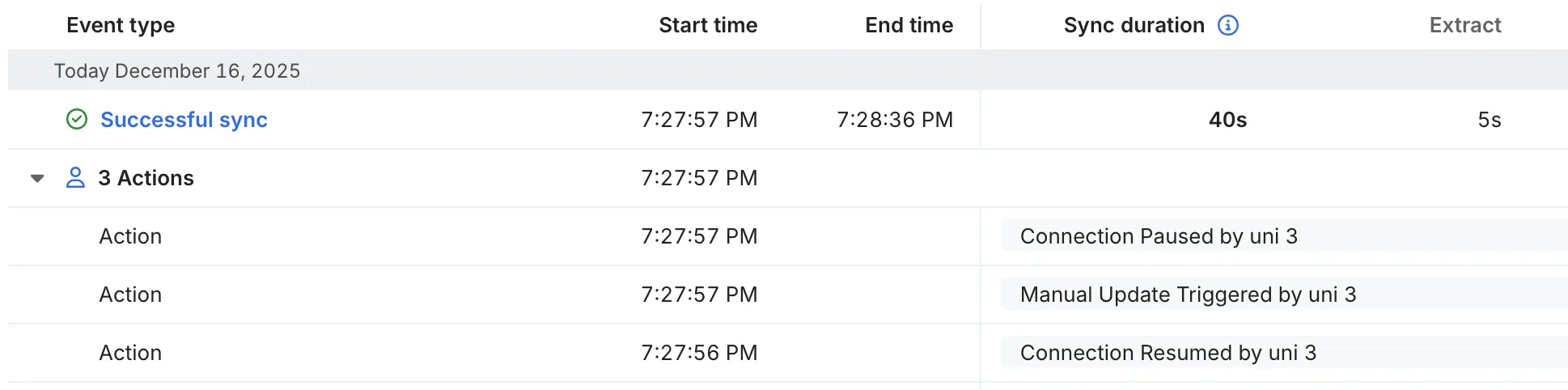
もちろんGUIからも実行可能。connection詳細ページの右上あたりからpause→enableの切り替え、syncで実行できる
github actions経由
実行コマンドなどはcli経由で使ったものと同じ
なんとなくgithub actionsで実装したが、airflowやprefectにもインテグレーション用にsdk等があるので、実際はそちらを使うとよい
connectionの作成
公式ドキュメントに丁寧に手順が書いてある。uvベースでやりたかったのでそのあたりの改修を入れている
https://fivetran.com/docs/connector-sdk/best-practices/creating-cicd-pipeline
- actionsファイル。ルートリポジトリの
fivetrans_project以下にプロジェクトを設置している
name: Deploy Fivetran Connector
defaults:
run:
working-directory: ./fivetrans_project
on:
push:
branches:
- main
paths:
- 'fivetrans_project/**'
- '.github/workflows/sync-fivetrans-connection.yml'
workflow_dispatch: {}
jobs:
deploy-fivetran-connector:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v6
with:
python-version: '3.14'
- name: Install uv
uses: astral-sh/setup-uv@v7
with:
enable-cache: true
- name: Install project dependencies with uv
run: uv sync --locked
- name: uv to requirements.txt for fivetran sdk
run: |
uv pip compile --output-file requirements.txt pyproject.toml
- name: Create Configuration File
run: |
echo "{\"app_id\": \"${{ secrets.ESTAT_APP_ID }}\"}" > configuration.json
- name: Deploy Fivetran Connector
env:
FIVETRAN_API_KEY_BASE64: ${{ secrets.FIVETRAN_API_KEY_BASE64 }}
FIVETRAN_DESTINATION_NAME: ${{ secrets.FIVETRAN_ESTAT_DESTINATION_NAME }}
FIVETRAN_CONNECTION_NAME: "load_estat"
run: |
uv run fivetran deploy --api-key "$FIVETRAN_API_KEY_BASE64" --destination "$FIVETRAN_DESTINATION_NAME" --connection "$FIVETRAN_CONNECTION_NAME" --configuration configuration.json --force実行
手動実行にしたかったのでトリガーはworkflow_dispatchのみ。CONNECTION IDをconnection作成後に設定しないといけないのが少し面倒である
- actionsファイル
name: Fivetran Sync Trigger
on:
workflow_dispatch: {}
defaults:
run:
working-directory: ./fivetrans_project
jobs:
sync:
runs-on: ubuntu-latest
env:
FIVETRAN_API_KEY_BASE64: ${{ secrets.FIVETRAN_API_KEY_BASE64 }}
FIVETRAN_CONNECTION_ID: ${{ secrets.FIVETRAN_CONNECTION_ID }}
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: trigger turn on
run: |
curl -fsS -X PATCH "https://api.fivetran.com/v1/connectors/$FIVETRAN_CONNECTION_ID" \
-H "Authorization: Basic $FIVETRAN_API_KEY_BASE64" \
-H "Content-Type: application/json" \
-d '{ "paused": false }'
- name: trigger sync
run: |
curl -fsS -X POST https://api.fivetran.com/v1/connectors/$FIVETRAN_CONNECTION_ID/force \
-H "Authorization: Basic $FIVETRAN_API_KEY_BASE64" \
-H "Content-Type: application/json"
- name: trigger turn off
run: |
curl -fsS -X PATCH "https://api.fivetran.com/v1/connectors/$FIVETRAN_CONNECTION_ID" \
-H "Authorization: Basic $FIVETRAN_API_KEY_BASE64" \
-H "Content-Type: application/json" \
-d '{ "paused": true }'感想
fivetran SDKはデータ取得やスキーマ定義に集中でき便利だ。デバッグも容易である。一方、destination側の詳細設定(パーティションキーやdescriptionなど)には未対応のようだ。ひとまず取り込み、dbtのstaging層などで型変換やパーティション設定を済ませる運用が想定されている。
転送、変換周りの処理がブラックボックスになり、通知や失敗時のログも参照しづらくなる懸念はあるが、小〜中規模のデータをとにかく取り込む用途に向いていそうである
参考
公式。ai agentにコーディングさせる手順も載っているなど、充実のドキュメント