hadoopクラスターを触ってみたくてdockerで構築してみた。クラスター自体はambariを使って構築した
環境
- Mac OS: 10.13.4
- docker: 18.03.0-ce
- docker-compose: 1.20.1
概要
正式名称はApache Hadoop、Apache Ambariらしい。apacheすごい
Apache Hadoopは分散処理を行うためのフレームワークであり、分散ファイルシステム(HDFS)やスケジューラ(YARN)などのモジュールからなる
Apache Ambariはhadoopクラスタの構成や管理をAPI、web画面上で行うことのできるツール
必要スペック
立ち上げた段階での使用量
- 容量
15GBくらい使ってる
docker images | grep hdp
REPOSITORY TAG IMAGE ID CREATED SIZE
hdp/postgres latest c0b9b10b2a1a 22 hours ago 307MB
hdp/ambari-server latest 35e511e93712 22 hours ago 2.86GB
hdp/node latest 51aa73fa4fef 26 hours ago 11.6GB- メモリ
6GBくらい使ってる
docker stats | grep hdp
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
ec59cc60438c ambarihdp_postgres.dev_1 1.28% 51.09MiB / 9.744GiB 0.51% 13MB / 40.5MB 14.2MB / 21.8MB 24
d8e6ee8d6c5f ambarihdp_dn0.dev_1 30.77% 5.216GiB / 9.744GiB 53.54% 31.2MB / 81.2MB 379MB / 71.3MB 1069
7f0876aac51a ambarihdp_ambari-server.dev_1 0.45% 640.8MiB / 9.744GiB 6.42% 123MB / 51.8MB 618MB / 20.5kB 66構築
ファイル数が多いので以下githubに設置しておく。GitHub - randerzander/docker-hdp: Dockerized HDP Clusterを参考にし、動くようにした
https://github.com/uni-3/docker/tree/develop/ambari_hdp
コンテナ作成
cd ./ambari_hdp
docker-compose build
...数GBインストールを行うので、時間がかかる
docker-compose up -d
ip-10-204-52-195:ambari_hdp 01156981docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------------------------------
ambarihdp_ambari-server.dev_1 /bin/sh -c /start.sh Up 0.0.0.0:8080->8080/tcp
ambarihdp_dn0.dev_1 /bin/sh -c /start.sh Up 0.0.0.0:10000->10000/tcp,
..(portsたくさんあるので省略)
ambarihdp_postgres.dev_1 docker-entrypoint.sh postgres Up 5432/tcp ambari UIはhttp://localhost:8080 でアクセスできる。デフォルトのユーザ名/パスワードはadmin/admin
クラスター作成
クラスター構築
ambariを使って、hadoopクラスターを作成する ホスト(mac)から以下のコマンドを実行する
sh submit-blueprint.sh single-container examples/blueprints/single-container.json
{
"href" : "http://127.0.0.1:8080/api/v1/clusters/dev/requests/1",
"Requests" : {
"id" : 1,
"status" : "Accepted"
}hiveのconfig更新
が、このままでは動かない。ambari UIで設定変更してやる必要がある
クラスターのダッシュボード(http://127.0.0.1:8080/#/main/dashboard/metrics) から
hive -> configをクリック
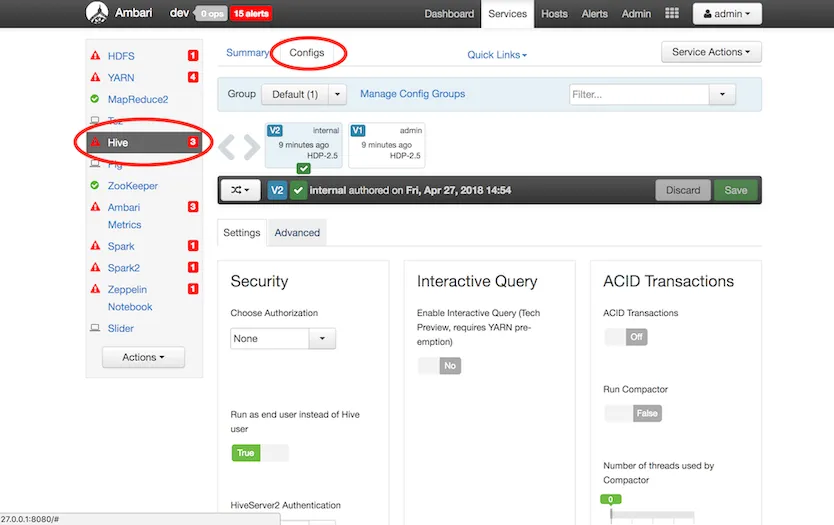
- advancedタブを開き
Database URLをjdbc:postgresql://postgres.dev:5432/hive、Database Passwordをdevに変更
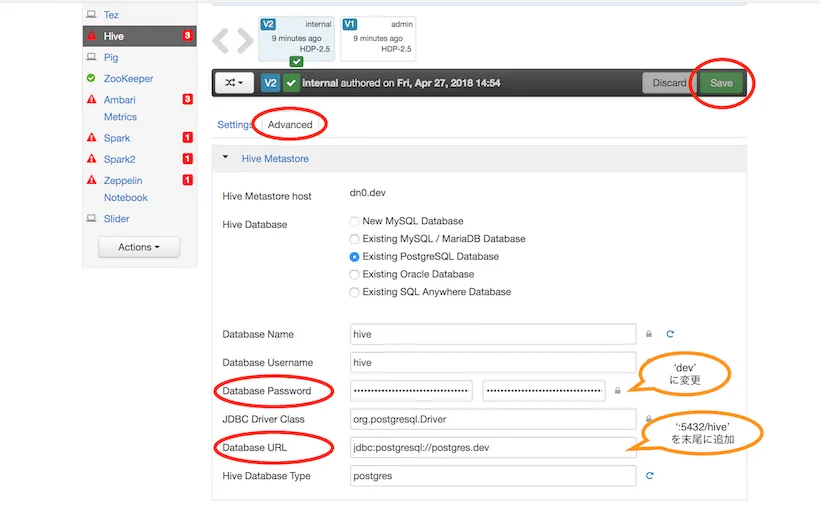
- saveすると表示されるrestartボタンをクリック
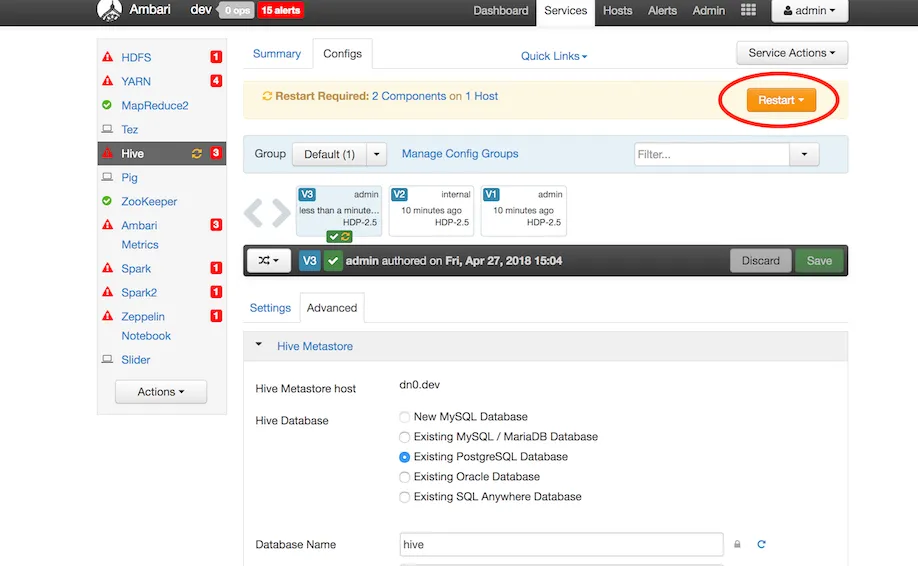
画面左上のdev部分を押すと、実行の進捗がわかる
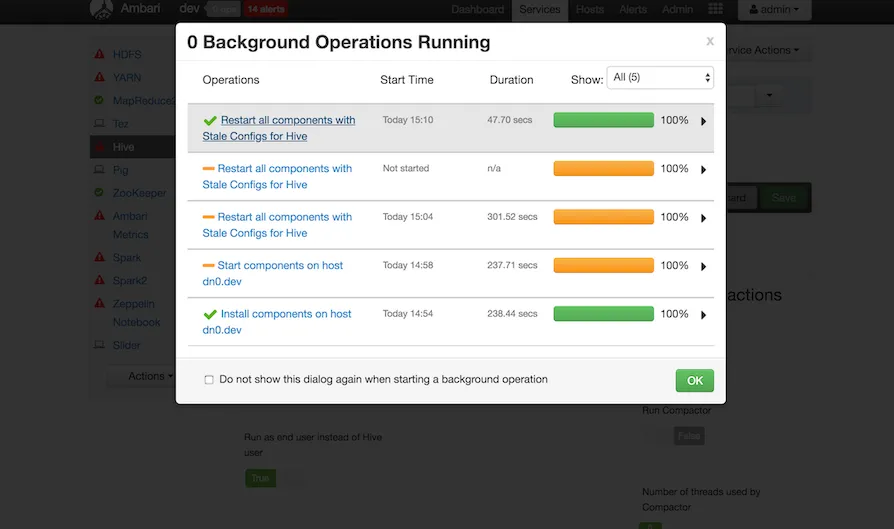
- 左サイドバー下部から
Actions -> Start Allを実行
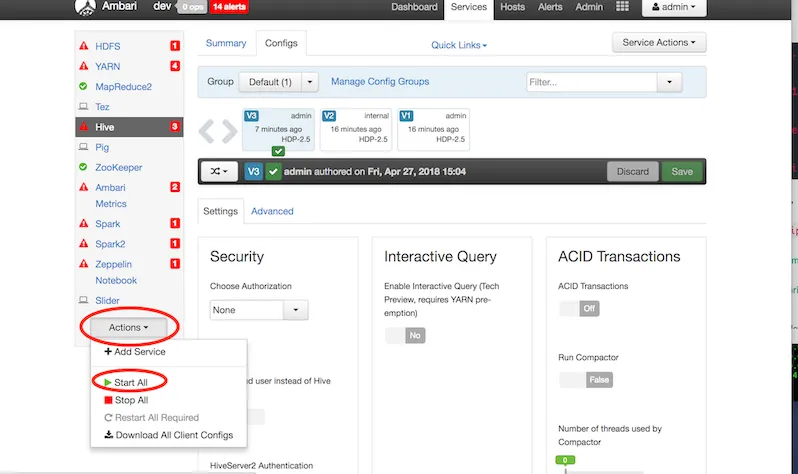
これで起動するはず
動作確認
cliでファイル操作やMapReduceっぽいことをしてみる
hdfs(hadoop)コマンドの確認
hdfsコマンドとhadoopコマンドがあるが大体同じらしい
hdfsコマンドは、基本hdfsユーザで操作するっぽいので
sudo -u hdfs hadoopなどとしてhdfsユーザとしてコマンドを実行していく
コマンドはクラスターのnodeコンテナにて実行していく
docker-compose exec dn0.dev /bin/bash sudo -u hdfs hadoop fs -mkdir -p /user/admin
Error: JAVA_HOME is not set and could not be found.JAVA_HOMEが環境変数にセットされていないらしい
/etc/profileファイルに
export JAVA_HOME=/usr/lib/jvm/jre-openjdk
sourse /etc/profileを追記して、設定を読み込む。(存在する*-openjdkをパスにしてみた) フォルダを作ってみる
sudo -u hdfs hadoop fs -mkdir -p /user/admin
sudo -u hdfs hadoop fs -chown admin /user/admin
hadoop fs -ls /user/
Found 6 items
drwxr-xr-x - admin hdfs 0 2018-04-23 02:20 /user/admin
drwxrwx--- - ambari-qa hdfs 0 2018-04-23 01:21 /user/ambari-qa
drwxr-xr-x - hcat hdfs 0 2018-04-23 01:52 /user/hcat
drwxr-xr-x - hive hdfs 0 2018-04-23 01:52 /user/hive
drwxrwxr-x - spark hdfs 0 2018-04-23 01:47 /user/spark
drwxr-xr-x - zeppelin hdfs 0 2018-04-23 01:48 /user/zeppelinフォルダできてる。権限も変更できてる
hiveの動作確認
hiveはhadoopのsqlみたいなもののこと データの収集、処理等はこれを使うことが多いらしい
hive
Logging initialized using configuration in file:/etc/hive/2.6.2.0-205/0/hive-log4j.properties
Exception in thread "main" java.lang.RuntimeException: org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/user/root":hdfs:hdfs:drwxr-xr-x
...めっちゃエラー出た。permissionの問題っぽい /userディレクトリに書き込みたいが、所有者はhdfsで、rootでは書き込み権限がない様子 hdfsユーザで実行すればよい
sudo -u hdfs hive
Logging initialized using configuration in file:/etc/hive/2.6.2.0-205/0/hive-log4j.properties
hive>できた
以下の操作をやってみる
- logファイルを読み込んでテーブルの作成
hive> create table loglines (line string);
OK
Time taken: 1.53 seconds
hive> load data local inpath '/var/log/ambari-agent/' overwrite into table loglines;
Loading data to table default.loglines
Table default.loglines stats: [numFiles=2, numRows=0, totalSize=1355148, rawDataSize=0]
OK
Time taken: 0.649 seconds- logを単語ごと(スペース区切り)で分けて、単語とその出現回数を別テーブルに保存
hive> create table words as
select word, count(*) as count
from (
select
explode(split(line, " ")) as word
from loglines
) a
group by word;
Query ID = hdfs_20180423030713_896aa234-0514-4afa-8a59-5142feab2e23
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1524448058442_0005)
--------------------------------------------------------------------------------
VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
--------------------------------------------------------------------------------
Map 1 .......... SUCCEEDED 1 1 0 0 0 0
Reducer 2 ...... SUCCEEDED 1 1 0 0 0 0
--------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 6.56 s
--------------------------------------------------------------------------------
Moving data to directory hdfs://dn0.dev:8020/apps/hive/warehouse/words
Table default.words stats: [numFiles=1, numRows=7082, totalSize=114758, rawDataSize=107676]
OK
Time taken: 9.306 seconds分散処理とかしてるのだろうか
テーブルの中身を見てみる
- loglinesテーブル
ログファイルが1行ずつ入っているはず
hive> select * from loglines limit 5;
OK
INFO 2018-04-23 01:14:33,721 main.py:145 - loglevel=logging.INFO
INFO 2018-04-23 01:14:33,721 main.py:145 - loglevel=logging.INFO
INFO 2018-04-23 01:14:33,721 main.py:145 - loglevel=logging.INFO
INFO 2018-04-23 01:14:33,723 DataCleaner.py:39 - Data cleanup thread started
INFO 2018-04-23 01:14:33,726 DataCleaner.py:120 - Data cleanup started
Time taken: 0.08 seconds, Fetched: 5 row(s)- wordsテーブル
wordとcountカラムがある
hive> select * from words limit 5;
OK
24578
"", 1
"/", 1
"/etc/ambari-metrics-collector"}, 1
"/etc/ambari-metrics-monitor"}, 1
Time taken: 0.076 seconds, Fetched: 5 row(s)ファイルでも出力されているっぽい
sudo -u hdfs hdfs dfs -cat hdfs://dn0.dev:8020/apps/hive/warehouse/words/000000_0 | head -n5
24578
"",1
"/",1
"/etc/ambari-metrics-collector"},1
"/etc/ambari-metrics-monitor"},1
cat: Unable to write to output stream.