dbt 触ったメモ bigquery につないでデータを触ってみた
環境
- dbt cloud
- dbt: v1.4
- dbt IDE: 編集、実行はこちらを用いた。編集実行などが思ったより簡単にできた
https://docs.getdbt.com/docs/running-a-dbt-project/using-the-dbt-ide
setup
接続して、編集、実行まで行う
接続先
bigquery jobユーザのロールを持ったサービスアカウントを作成して、 Key JSON 生成、ダウンロードして、dbt画面にアップロードする
接続テストして完了
- Create Project
- Database Connection
- Add Repository githubの場合はアカウント連携する。integrationの設定をして、あらかじめ作成したdbt用のリポジトリにdbtを連携する
権限的にはviewの作成をするのでデータセットの編集。ジョブユーザを割り当てた
保存先のdataset
profileの環境設定から変更する
profile → credentials →Development Credentials
https://cloud.getdbt.com/#/profile/projects/137868/credentials/
project内で環境ごとに設定し、projectIDやdatasetをいれておける
実行
model/に入れたsqlファイルが実行され、クエリ結果をテーブルとして作成する
↓こんなsqlを作った
https://github.com/uni-3/dbt-tutorial/blob/main/models/ga4/pv_in_30_days.sql
create tableなんかの文をかかなくても作れてしまうのは手軽でよさそう
GUI のコマンドから
dbt run --select pv_in_30_days定期実行
jobという機能を使う
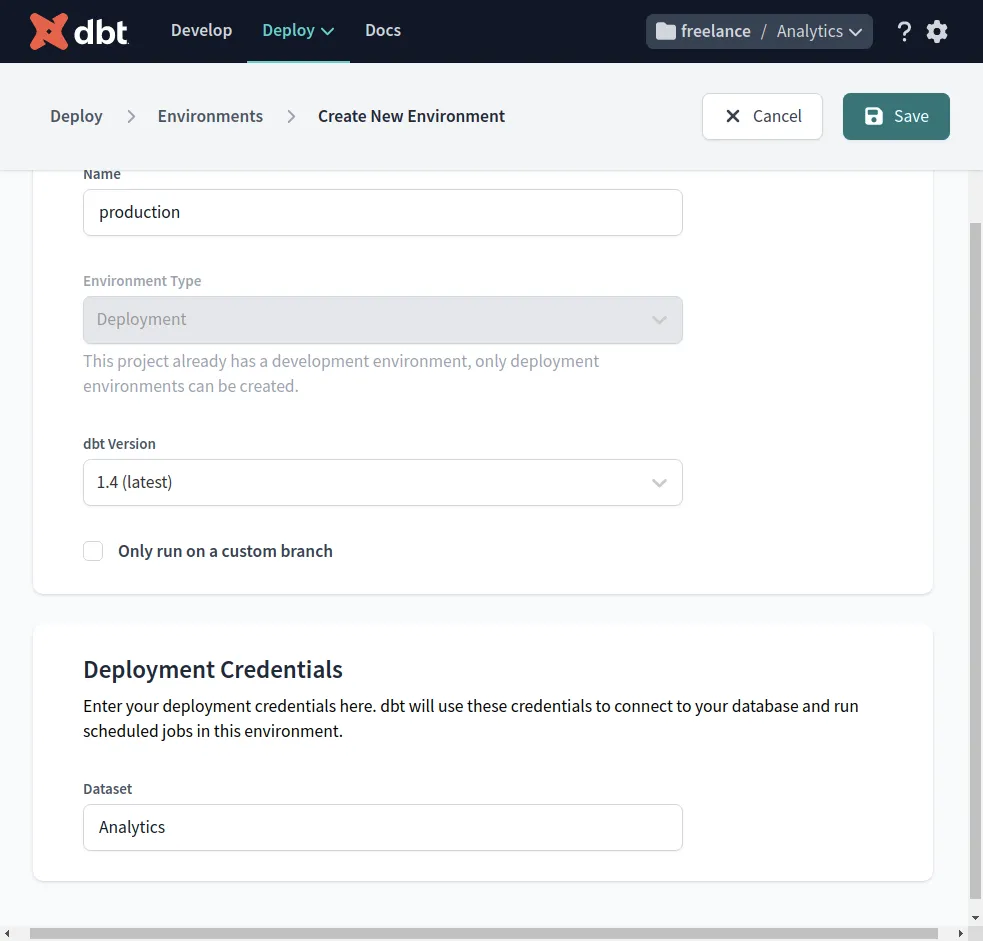
Deploy → Environments → Create New Environment
Datasetにproject名(ここではAnalytics)を設定する
Environments より、Create Jobから作成、スケジューラーの設定ができる
https://docs.getdbt.com/guides/getting-started/building-your-first-project/schedule-a-job
おまけ ドキュメントで気になった部分のメモ
- modelファイルでDMLを使わない理由
dbtのsql構文は内部で独自に定義しているらしい。サポートしているDBなんかについて変換される
これは以下のような問題に直面するのを避けるためとのこと
- テーブルがすでに存在しているときの処理
- スキーマがすでにあるときの処理
- model(table/view)なんかをreplaceするとき作成し直す処理の考慮
- スキーマのパラメータ化。特に環境によるもの
- 文の実行順序の考慮
- SQLの構文はDML
https://docs.getdbt.com/docs/building-a-dbt-project/building-models
のFAQsより