ソースデータ取得から加工まで。一連を試すだけなので取得と変換はexample程度のものになっている
ついでに使ってみたかったツールも色々(pyairbyte、dbt、duckdb)
環境
- python: 3.11
- dagster: 1.8
- dagster-dbt: 0.23.12
- dbt(dbt-core): 1.8.3
- airbyte(pyairbyte): 0.15.0
- duckdb: 1.0.0
install方法は割愛。全てpythonライブラリとしてインストールできる
構成
- dagster
ワークフローツールとしてジョブの構成、実行環境として用いた
- pyairbyte
extract&loadで用いた。airbyteのconnectorを簡単に利用できる、また任意のdatabeseへのcacheを行いincremental loadを行う機能を持つ点が気に入った
- dbt
transformで用いた。dagsterとのintegrationが気になってやってみた
- duckdb
pyairbyteのcache、データの格納先として用いた
流れ。大体、各ツールのexample詰め合わせ
githubリポジトリからissue一覧の取得->格納->作成日別issueの数をカウント
ディレクトリ
dagster
- assets
- pyairbyte_project
このディレクトリ以下にpyairbyteにて必要なモジュール(with venv)やキャッシュの情報が保存される
- githubリポジトリからissueのデータを取得する
- dbt
dbt_projectから色々読み込んでassetを定義する
- issueの日付別カウントを集計
- pyairbyte_project
このディレクトリ以下にpyairbyteにて必要なモジュール(with venv)やキャッシュの情報が保存される
- resources
assetで使用するdbなどの接続情報
- duckdb
- cache(duckdb)
- dbt
- dagster_pyairbyte_dbt
諸々モジュールを読み込んでdefinitionを設定(プロジェクト内の資産や依存関係を定義する)
- 本来、job関連はjobsモジュール以下に定義しておくとよいが、プロジェクト直下にかいている
- dbt_project dbtのproject、データソースはduckdbを使う
コード断片
全体はリポジトリに入れている
かいていてちょっと大変だったところを抜き出しておく
- resourceの定義をassetに渡す resouceとして必要な情報を外部から渡したいときなど
assetモジュール
from dagster_duckdb import DuckDBResource
from dagster import EnvVar, resource
import airbyte as ab
database_resource = DuckDBResource(
database=EnvVar("DUCKDB_DATABASE"),
)
# pyairbyteのキャッシュリソース
@resource
def pyairbyte_cache_resource(_):
return ab.get_default_cache()assetの定義
@asset(
name="issues",
group_name="airbyte_sources",
compute_kind="DuckDB",
required_resource_keys={'cache', 'database'},
)
def github_issues(context: OpExecutionContext):
repo_name = "airbytehq/quickstarts"
stream_name = "issues"
cache = context.resources.cache
db = context.resources.database
...definition(project直下のコード)
ここでresourcesに渡した情報がcontextに格納される
defs = Definitions(
assets=github_issues_assets + dbt_project_assets, # assetの依存
resources={
"database": database_resource,
"cache": pyairbyte_cache_resource,
"dbt": dbt_resource,
},
jobs=[all_asset_job, pyairbyte_asset_job, dbt_dep_job]
)Definitionというもので必要なジョブやらリソースやらを宣言しており。1モジュールに1つ定義できる。これを基にprojectの情報が生成されるっぽい
結果
生成されるassetなどを見てみる
GUI
dagster devにて立ち上がるUIから、定義したjobなどがみれる
- asset
依存関係込みで表示される。画面から実行もできる
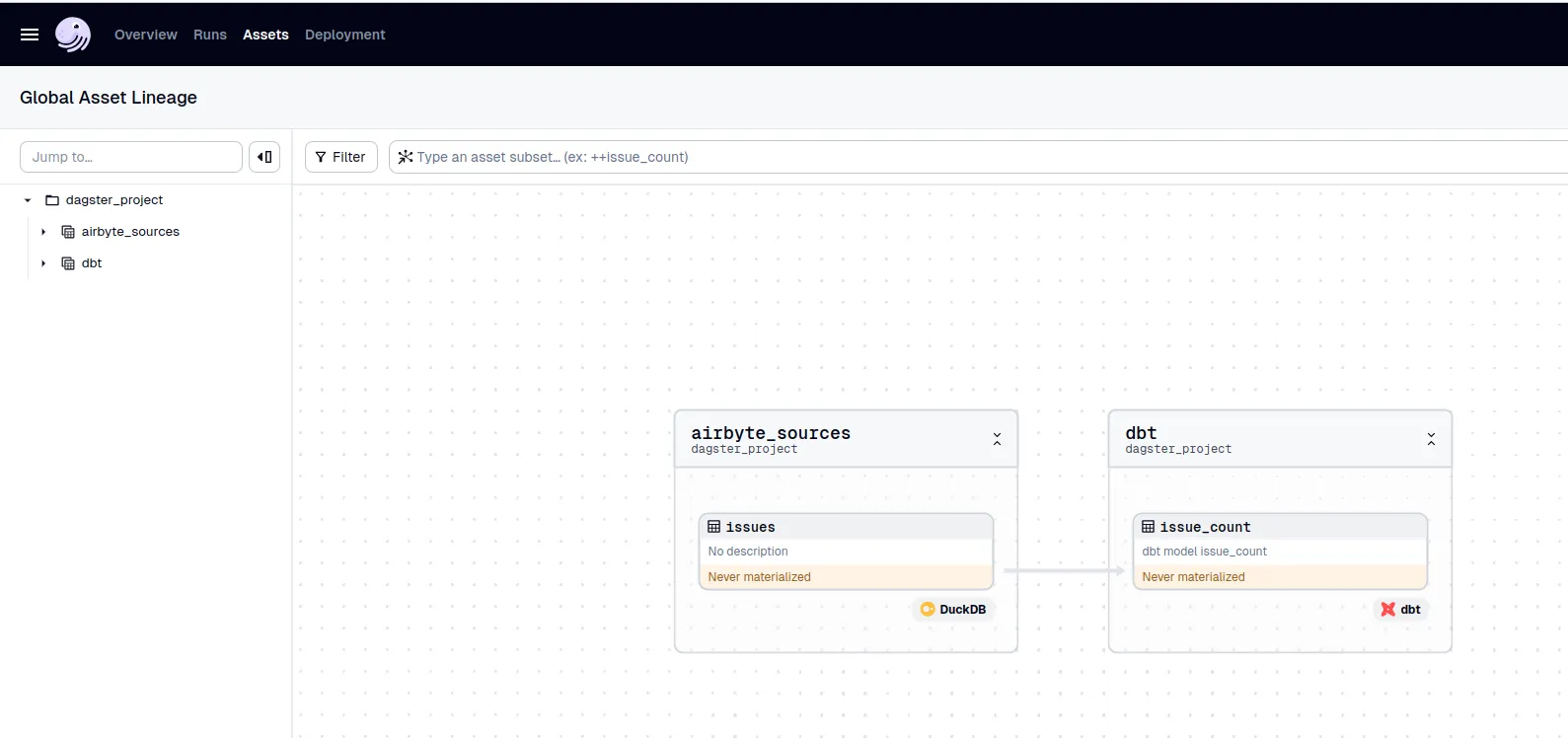
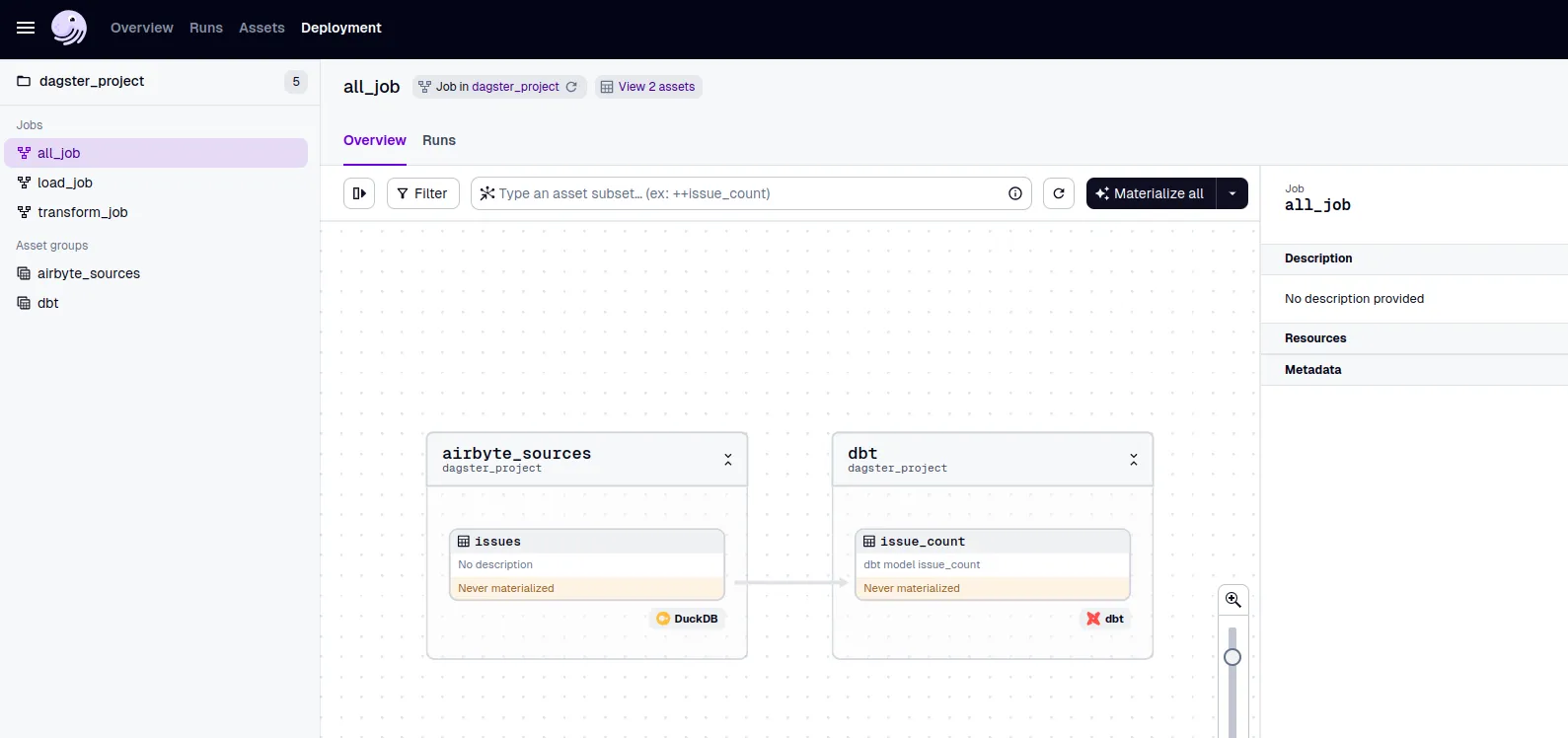
- job
CLI
- asset
asset名のissuesはpyairbyteの@assetの引数から、issue_countはdbtのファイル名にて宣言している
dagster asset list -m dagster_pyairbyte_dbt
issue_count
issues- job
jobの情報を見ると各asset生成順序もわかる
dagster job list -m dagster_pyairbyte_dbt
...
Repository __repository__
*************************
Job: __ASSET_JOB
Ops: (Execution Order)
issues
dbt
************
Job: all_job
Ops: (Execution Order)
issues
dbt
*************
Job: load_job
Ops: (Execution Order)
issues
******************
Job: transform_job
Ops: (Execution Order)
dbtgui。グラフやリスト形式で表示される
感想
ETLとかELTを一連のワークフローで定義できるかどうか試してみた。pythonスクリプトのみで割と柔軟にできそう。実用性を鑑みるとbackfillなど、他にも試したい動作はあったが動くところまでで力尽きた
- dagster
assetの依存関係の定義、この書き方にたどり着くの割と大変だった
assets=github_issues_assets + dbt_project_assets,assetの準備にはたいていextract→load(→transform)の流れで行うが、各手順を独立して実行したいときや依存関係の定義はどうしておくといいのかと思ったらドキュメントみつけた。opは今回試さなかった
https://docs.dagster.io/guides/dagster/how-assets-relate-to-ops-and-graphs
基本的にプロジェクト構成が決まっており、ワークフローツールもフレームワーク感の強いものが出てきたなと感じる。構成を考えなくてもいいのでそのあたりの標準化は楽にできそう。resourceとして用いるdbの定義をassetにinjectionっぽくかけるところとか、それっぽい
そのかわりjobの分割単位など、定義とお作法周りを適切に理解する難易度は高そう。新しい用語や概念もあるし、巷の評判通り学習コスト高いツールだなと感じた
- pyairbyte
事前定義されているsourceも多様で、incrementalロードも簡単に実装できそう。手軽にいろいろ考慮をしたloadができる印象
destinationの例もあった。試してないがload部分をスクラッチで書く必要はもなくなってきている
https://github.com/airbytehq/PyAirbyte/blob/main/examples/run_bigquery_destination.py
https://github.com/airbytehq/PyAirbyte/blob/main/airbyte/destinations/base.py#L66
意外と全部pythonライブラリになっているのでワークフローツールさえなんとかすれば実行環境は楽に整えられそうな時代になっている