cube.jsはheadless BIの一種。集計クエリを効率的に処理するためのオープンソースのデータ分析フレームワークであり、さまざまな集計条件について、APIで簡単に取得できる。ga4のbigquery exportデータについて適当に集計してみた
環境
- cube.js: 0.33
- docker compose: 2.2.3
docker compose
公式imageがあるので簡単。キャッシュやらdbのサーバーも同じimage内に立ち上がるらしい
接続先の db は bigquery。env にいろいろ設定値をいれる
- docker-compose.yml
CUBEJS_API_SECRET/CUBEJS_DEV_MODE はこれがないとうごかなかった
application_default_credentials.json は gcp console からダウンロードした iam なんかの json キーのこと
./cube/conf/schema 以下に集計定義ファイルなんかが設置されていく
version: '3'
services:
cube:
image: cubejs/cube:latest
ports:
- 4000:4000
- 15432:15432
volumes:
- ./cube/conf:/cube/conf
- ~/.config/gcloud/application_default_credentials.json:/key.json:ro
environment:
- CUBEJS_DB_TYPE=bigquery
- CUBEJS_DB_BQ_PROJECT_ID=${project_id}
- CUBEJS_DB_BQ_KEY_FILE=/key.json
- GOOGLE_APPLICATION_CREDENTIALS=/key.json
- CUBEJS_DEV_MODE=true
- CUBEJS_API_SECRET=SECRET
- CUBEJS_WEB_SOCKETS=true
- CUBEJS_TELEMETRY=falsega4 export data
テーブルは以前の記事にて作成したものを使用する
生データで試そうとしたが、event_params などの RECORD 型はスキーマに定義されなかったためフラット化したものを使った
例1 スキーマ読み込みと事前集計
スキーマ import
docker compose up すると localhost:4000 にcube.jsのクライアントがたち上がる。data modelタブを選択し、しばらくすると指定したprojectのスキーマ並びにテーブルが一覧表示される
適当なテーブルを選んで
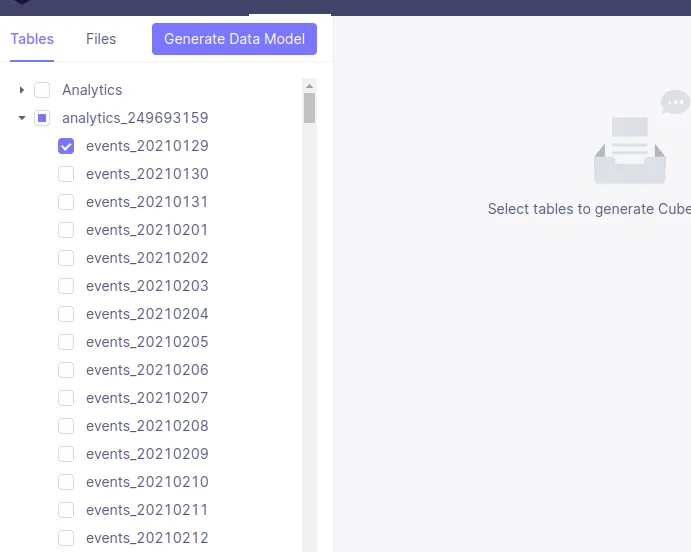
Generate Data Model をクリックすると schema/cubes 以下にスキーマ定義ファイルが生成される。中身は割愛する
dimensionには既存のスキーマが入る。idがprimary_keyになったりするので削除した
集計値定義
measureとしてPV数とUU数なんかを定義してみる
measures:
...
- name: pv
type: count
filters:
- sql: "event_name='page_view'"
- name: uu
sql: user_pseudo_id
type: count_distinct
- name: pv_per_user
description: "一人あたりページビュー数"
sql: "{pv} / {uu}"
type: number
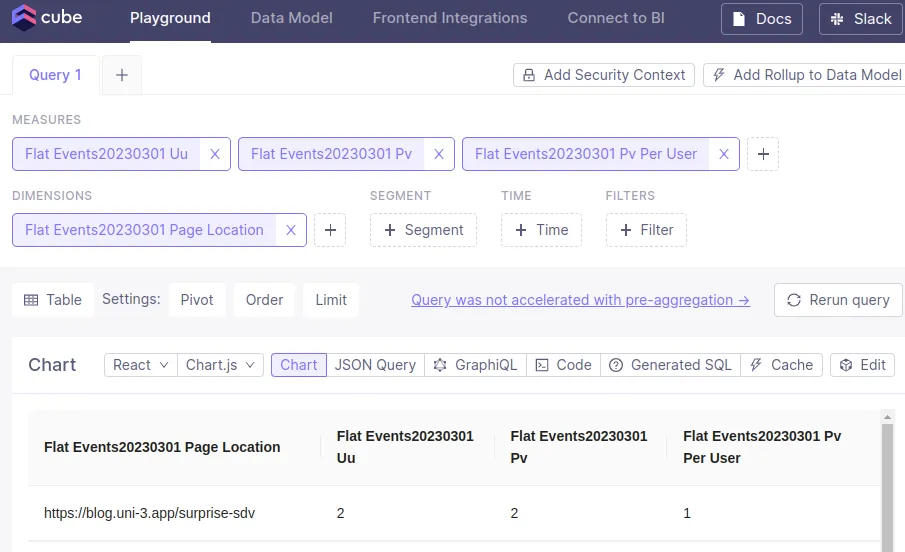
実際の集計はplaygroudタブから試すことができる
画像はページロケーションごとの数値。dimensionsに適当な値を設定するとそれ用の集計が行われる
pre_aggregations
事前に集計しておきたい組み合わせを定義しておくと、実際にテーブルが作成される。あらかじめ計算されたテーブルを参照するので、クエリの応答時間短縮になる
上記画像ではpre_aggreagationが無効になっている旨が表示されている
pre_aggregationsの項目にスキーマ定義をかいておくと
cubes:
- name: flat_events_20230301
...
pre_aggregations:
- name: page_uu
measures:
- flat_events_20230301.uu
- flat_events_20230301.pv
dimensions:
- flat_events_20230301.page_location以下のようなテーブルが作成されていた
${project_id}.dev_pre_aggregations.flat_events_20230301_page_uu_gvsfah1n_lztcwm3s_1iciei1
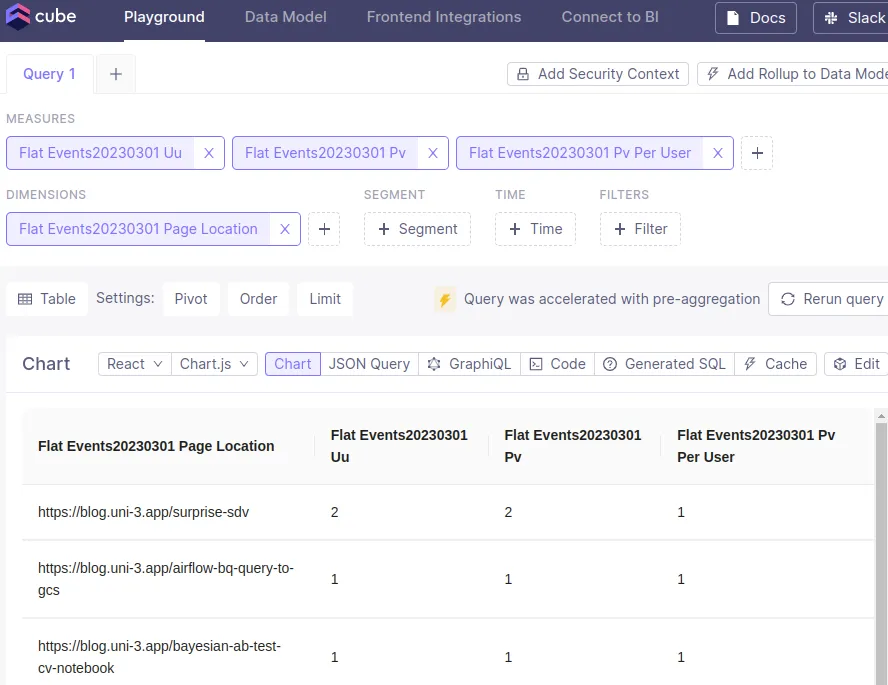
実際にplaygroundから集計し、pre-aggregationが有効になっているかどうかが確認できる
例2 ワイルドカードテーブルの_table_suffix条件指定と、全体集計値
複雑な集計をさせてみた
スキーマはこんな感じ
cubes:
- name: analytics
sql: select * from `analytics_249693159.flat_events_202303*`
measures:
- name: uu
sql: user_pseudo_id
type: count_distinct
drill_members:
- page_location
- name: total_uu
sql: "(SELECT COUNT(DISTINCT user_pseudo_id) FROM `analytics_249693159.flat_events_202303*` where {FILTER_PARAMS.analytics.date.filter('_table_suffix')})"
type: number
- name: uu_rate
sql: "100 * safe_divide({uu}, {total_uu})"
type: number
format: percent
dimensions:
- name: page_location
sql: page_location
type: string
- name: page_referrer
sql: page_referrer
type: string
- name: user_pseudo_id
sql: user_pseudo_id
type: string
- name: date
sql: _table_suffix
type: string全体のUU数とdimensionごとのUU数の割合
サブセットの集計値と全体に対する集計値を用いた指標を定義できるか試してみた 例えば全体のUU数に対するページロケーションごとのUU数の割合などが計算できる
クエリで実現するなら、例えばwith句などを使ってCTEテーブルを作成し、cross joinして計算できる
全体のUU数は total_uu として定義した。もしくはcubes直下のsqlにかいておくのでもよさそう。sqlで定義しているので、dimensionsの値が指定されていてもその影響は受けない
uu_rateとして全体UUに対する任意のdimensionの組み合わせのUUの割合をパーセントで定義している
集計軸の粒度を1つのcube内で楽にできるかと思ったが、案外 sql をかいておく必要がある。わかりやすくするならcubeを分けてしまってjoinさせるほうがよい場合もありそう
_table_suffix の指定
ワイルドカードテーブルなので、任意の期間についてクエリを実行できるようにしたい。filterを指定し、生成されるクエリにwhereとして条件が入るのを確認すればよい
cubes直下のanalyticsに”sql: select * from analytics_249693159.flat_events_202303*”として指定した。sql_tableプロパティだと * の値が有効にならず、_table_suffixの指定ができなかった
また、total_uu のsql に{FILTER_PARAMS.analytics.date.filter('_table_suffix') などとかいておくと、以下のようなクエリが生成される。stringで入力することになるので、inでの指定になるが、一応指定した日付のテーブルから取得はできる
(
SELECT
COUNT(DISTINCT user_pseudo_id)
FROM
`analytics_249693159.flat_events_202303*`
where
_table_suffix IN (?, ?, ?, ?, ?)
) `analytics__total_uu`,
本来ならtime型にして範囲指定したかったが、ymlではできなかった。.jsで任意のフォーマットを行えるとあるのでそちらを使うのもよさそう
https://cube.dev/docs/product/data-modeling/reference/cube#filter-params
playgroundで出してみるとこんな感じ
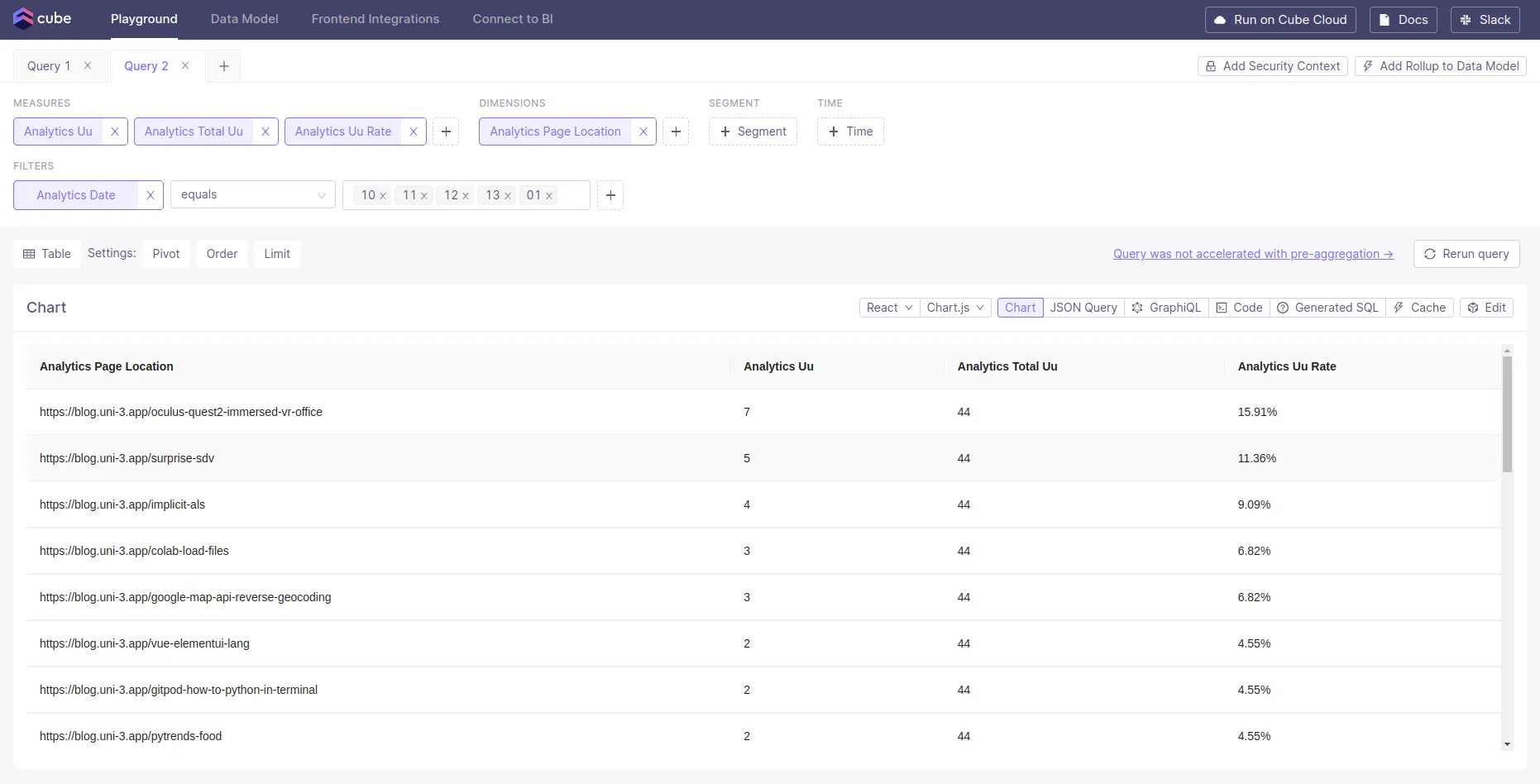
api のリクエストはこんな感じ。dimensionsの指定をpage_referrerにしたりすることで、集計単位を変えることができる
curl -X POST -H "Content-Type: application/json" -d '{"query":{"measures": [ "analytics.uu", "analytics.total_uu", "analytics.uu_rate" ], "order": { "analytics.uu_rate": "desc" }, "dimensions": [ "analytics.page_location" ], "filters": [ { "member": "analytics.date", "operator": "equals", "values": [ "20", "21" ] } ] }}' http://localhost:4000/cubejs-api/v1/load所感
- データの取得が便利
api や sdk での取得もできるので、
複雑な集計単位のクエリをパラメータなどをつかって組み立てるロジックを組まずにすむのでよさそうである
- 集計軸と指標が定義できる
DWHのデータはなにをするでも集計軸が多く、BIツール以外でDWHのデータを使うことが現実的ではない(アドホックなクエリをかいて対応しがち)。そういう場合、インターフェイスとしてcubejsを用意しておけば、集計軸や指標の計算をクエリとして組まなくてもよくなりそう
ここまでやってみて looker で同等なことができる、かつ同じような書き方になりそうだった。looker を使っているならば、使い分ける意味はあまりなさそうでもある
参考
- headless BIについて
https://data.wingarc.com/all-about_bitool_08-43481
- cube.js の公式