cloud ML APIsはCloud Natural Language APIやCloud Speech-to-Text
などのgoogleが用意した学習済みAIを試せるAPI群のこと
こちらに一通り使い方が書いてあるノートブックがあったので簡単に試してみた
セットアップ
- プロジェクト作成 & 請求先の登録
- APIs & Servicesからapi keyの作成
- APIs & Servicesからapiの有効化
の手順を行う。このへんを参考に設定する
-
プロジェクトを作る https://cloud.google.com/resource-manager/docs/creating-managing-projects
-
請求先の登録 https://cloud.google.com/billing/docs/how-to/manage-billing-account
-
apiの有効化 https://cloud.google.com/apis/docs/enable-disable-apis
-
api keyの作成 https://cloud.google.com/docs/authentication/api-keys
このときapi keyは上ページのようにApplication restrictionsはNoneにしておく(google coraboratoryからリクエストできるように)
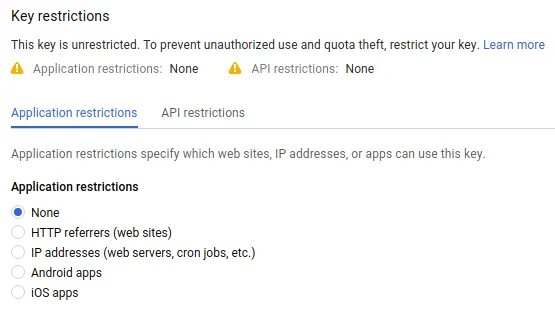
![api-key-application-restrictions.png]
(https://qiita-image-store.s3.amazonaws.com/0/189840/8f1700c1-d632-523a-6872-9be9bdb9c9f2.png)
{kind=link}
実行
google colaboratory上で行う
api keyの設定
import getpass
APIKEY = getpass.getpass()を実行すると下画像のように入力フォームが出てくるので 作成したapi keyを入力してエンターキーを押す
Cloud Natural Language API
文章の分かち書き、固有名詞の抽出、ポジネガ分析をまとめて行う 実行方法はこんな感じ
googleのapiなのでgoogle社の口コミを使ってみる
https://en-hyouban.com/company/10053079977/kuchikomi/3324058/
こちらの口コミを試してみる
from googleapiclient.discovery import build
lservice = build('language', 'v1beta1', developerKey=APIKEY)
ort json
quotes = [
'外資系企業なので日系の企業から転職した場合企業カルチャーに慣れるのに少し時間がかかるかもしれません。スピードが速く、社内はとてもフラットなカルチャーです。仕事の仕方もとても自立的で上司の指示等も日系企業ほど仰ぐ必要がないかもです。'
]
for quote in quotes:
response = lservice.documents().annotateText(
body={
'document': {
'type': 'PLAIN_TEXT',
'content': quote,
'language': 'ja'
},
'features': {
"extractSyntax": True,
"extractEntities": True,
"extractDocumentSentiment": True,
},
}).execute()
print('原文:', quote)
print('分かち書き:')
for token in response['tokens']:
print(token['text']['content'])
print('res', json.dumps(response, indent=2, ensure_ascii=False))printされる文。日系と取れたり日 系と取れたりしている
文章の極性(polarity)も怪しい感じがする
原文: 外資系企業なので日系の企業から転職した場合企業カルチャーに慣れるのに少し時間がかかるかもしれません。スピードが速く、社内はとてもフラットなカルチャーです。仕事の仕方もとても自立的で上司の指示等も日系企業ほど仰ぐ必要がないかもです。
分かち書き: 外資 系 企業 な ので 日系 の 企業 から 転職 し た 場合 企業 カルチャー に 慣れる の に 少し 時間 が かかる かもしれません 。 スピード が 速く 、 社内 は とても フラット な カルチャー です 。 仕事 の 仕方 も とても 自立 的 で 上司 の 指示 等 も 日 系 企業 ほど 仰ぐ 必要 が ない かも です 。
res {
"sentences": [
{
"text": {
"content": "外資系企業なので日系の企業から転職した場合企業カルチャーに慣れるのに少し時間がかかるかもしれません。",
"beginOffset": -1
},
"sentiment": {
"polarity": 1,
"magnitude": 0,
"score": 0
}
},
{
"text": {
"content": "スピードが速く、社内はとてもフラットなカルチャーです。",
"beginOffset": -1
},
"sentiment": {
"polarity": 1,
"magnitude": 0.5,
"score": 0.5
}
},
{
"text": {
"content": "仕事の仕方もとても自立的で上司の指示等も日系企業ほど仰ぐ必要がないかもです。",
"beginOffset": -1
},
"sentiment": {
"polarity": -1,
"magnitude": 0.5,
"score": -0.5
}
}
],
...
Speech to Text API
GCSにアップロードした音声ファイルを試す
https://qiita.com/noppefoxwolf/items/2f3831f7be159922795f#%E6%A8%A9%E9%99%90%E5%A4%89%E6%9B%B4
を参考にbucketをpublicアクセス設定しておかないと403が起きた
ファイル形式は.flac、サンプルレートは44100のものを用いている
import json
sservice = build('speech', 'v1beta1', developerKey=APIKEY)
response = sservice.speech().syncrecognize(
body={
'config': {
'encoding': 'FLAC',
'sampleRate': 44100,
'languageCode': 'ja-JP'
},
'audio': {
'uri': 'gs://"bucketname"/example.flac'
}
}).execute
print('res', json.dumps(response, indent=2, ensure_ascii=False))
---
res {
"results": [
{
"alternatives": [
{
"transcript": "6月19日...",
"confidence": 0.9313912
}
]
}
]
}他のapiも簡単に試せそうなので手元のデータを簡単に試せるツールとして使っていきたい