wildcard tableはテーブル名に任意のsuffixをつけて作成することで クエリの際、wildcardを使ってテーブルスキャン範囲を指定できる便利機能のこと
データ取得の際など、スキャン範囲を簡単に指定できるので重宝する。作成する際のスキーマの管理方法をどうするかなど、試したことを残しておく
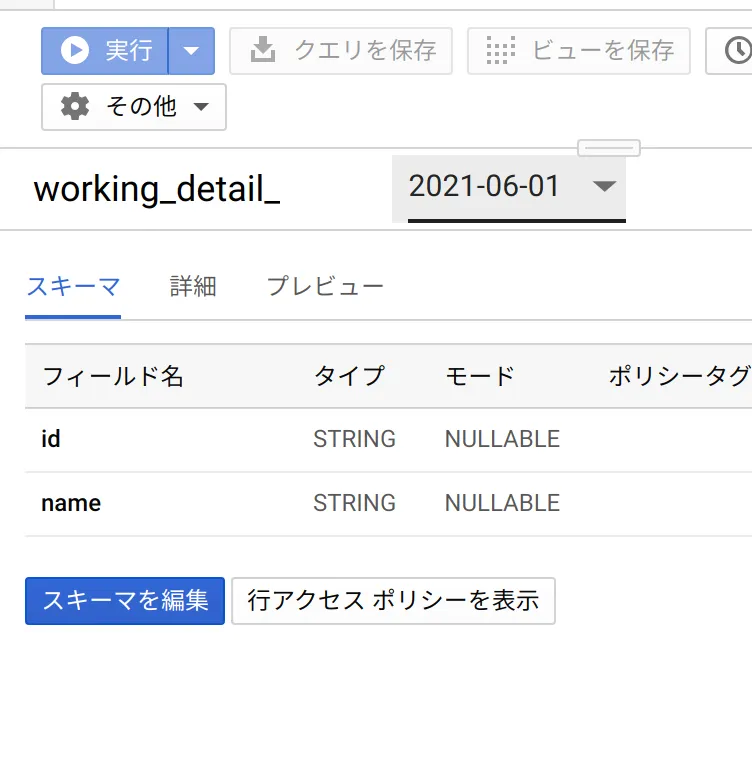
テーブル作成時のスキーマ定義
基本的にテーブルとしては別扱いになる
画面上でまとまって見えていても別テーブルなので、スキーマは異なっていても問題ない
例えば↓のようなテーブルを作成できる。テーブル名とかカラムは適当
console上では日付部分(20210701)などがまとまって表示される
CREATE TABLE `working_detail_20210601`
(
id STRING
name STRING
);
CREATE TABLE `working_detail_20210701`
(
title STRING
)
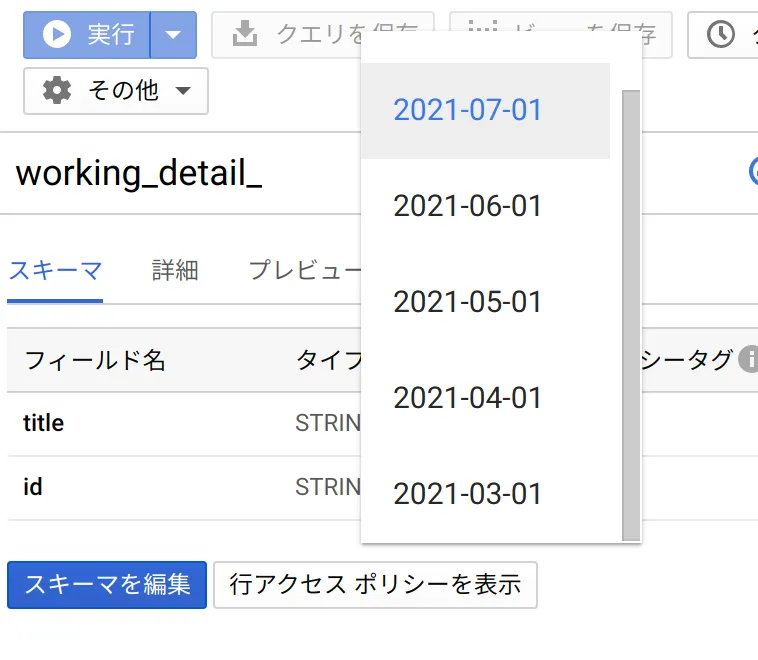
もちろんスキーマの追加もできる
bq update `working_detail_20210701` ./schema.json
# schema.json
[
{
"name": "title",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "id",
"type": "STRING",
"mode": "NULLABLE"
}
]これより、スキーマ定義はwildcard tableを作る際に指定する
クエリするテーブルが異なるスキーマをもつとき
どうやらカラム情報は最新のテーブルを参照する(ここでは20210701のものを参照する)
例えば、以下を実際にクエリするとUnrecognized name: name at [3:3]などとでる
selectの値をtitleだけにすると実行は通る
SELECT
id
,name
,title
FROM `working_detail_*`
WHERE _TABLE_SUFFIX BETWEEN '20210501' AND '20210701'念の為スキャン範囲変えたりcliで試しても同じだった
bq query --use_legacy_sql=false \
'SELECT
id
,name
,title
FROM `working_detail_*`
WHERE _TABLE_SUFFIX BETWEEN "20210501" AND "20210601"'どのテーブルであってもスキーマ定義は統一しておくとよさそうである
所感
公式ドキュメントなんかの例をみると、すでにあるテーブルの特定列(国名など)のdistinctをsuffixに使う、などとしていたりする
新規作成するものと言うより、後々分割したい単位ができた時にwildcard tableとして転写する用途を想定しているのだろう
分割単位が日付であればパーティションテーブルを使う選択肢もありえる
参考
- https://cloud.google.com/bigquery/docs/reference/standard-sql/wildcard-table-reference?hl=ja
- https://cloud.google.com/bigquery/docs/reference/bq-cli-reference?hl=ja#bq_show
- https://qiita.com/Hyperion13fleet/items/32e54651d8a0b82f842c
- https://cloud.google.com/bigquery/docs/creating-partitioned-tables#bq_1