search consoleのデータもbigqueryへexportできるようになっていたので試した。2023/02から追加された機能だそう
https://developers.google.com/search/blog/2023/02/bulk-data-export?hl=ja
export設定
以下のページが詳しいので具体的な手順は割愛する。google cloudにてサービスアカウントを作成する必要がある点に注意
>[新しいプリンシパル] に、次のサービス アカウント名を貼り付けます。
> search-console-data-export@system.gserviceaccount.com
>[BigQuery ジョブユーザー](コマンドライン インターフェースの bigquery.jobUser)と [BigQuery データ編集者](コマンドライン インターフェースの bigquery.dataEditor)という 2 つのロールを付与します。設定完了したあとの画面
searchconsoleデータ
テーブル
以下3つのテーブルが作成される
- searchdata_site_impression: プロパティ別に集計されたプロパティのパフォーマンス データが含まれます。
- searchdata_url_impression: URL 別に集計されたプロパティのパフォーマンス データが含まれます。
- ExportLog: 以前のデータテーブルのいずれかに対する成功したエクスポートごとの情報が含まれます。通常、Search Console はこれらのテーブルに個別にエクスポートを行います。失敗したエクスポートの試行はここには記録されません。
ref. https://support.google.com/webmasters/answer/12917991?hl=ja
数値データが入っているimpressionという名前のつくテーブルはイベント発生日(data_date)のカラムでpartitionが設定されている
イベント発生日はdate型であるが、太平洋時間(PST)に発生したもので集計されることに注意
https://support.google.com/webmasters/answer/12917991?hl=ja
転送頻度
logのテーブルから転送頻度やデータの遅れがどれくらいになりそうかみてみる
クエリ
SELECT
data_date,
-- 転送が開始した時間
EXTRACT(HOUR FROM DATETIME(publish_time, 'Asia/Tokyo')) AS publish_hour_jst,
-- データ更新の遅れ
DATE_DIFF(DATE(publish_time), data_date, DAY) AS publish_time_data_date_diff_day,
-- 前回更新時刻からの経過時間
TIMESTAMP_DIFF(publish_time, LAG(publish_time, 1) OVER (ORDER BY publish_time), HOUR) AS publish_freq_hour
FROM
`searchconsole.ExportLog`
WHERE
namespace = "SEARCHDATA_SITE_IMPRESSION"
ORDER BY
data_date図にしてみる(コンソール上で出せる図を用いているので少し見づらいが)。おおよそ、夕方〜夜にデータが更新されており、転送頻度はおよそ24時間なっていることがわかる。またデータの遅れは2日くらいで、GA4と同じ程度の遅れが発生するとみなせそう
グラフの赤線がデータ更新の遅れで、日数を表す。水色線が転送開始時刻で、時間を表す。青線が前回更新時刻からの経過時間で、時間を表す
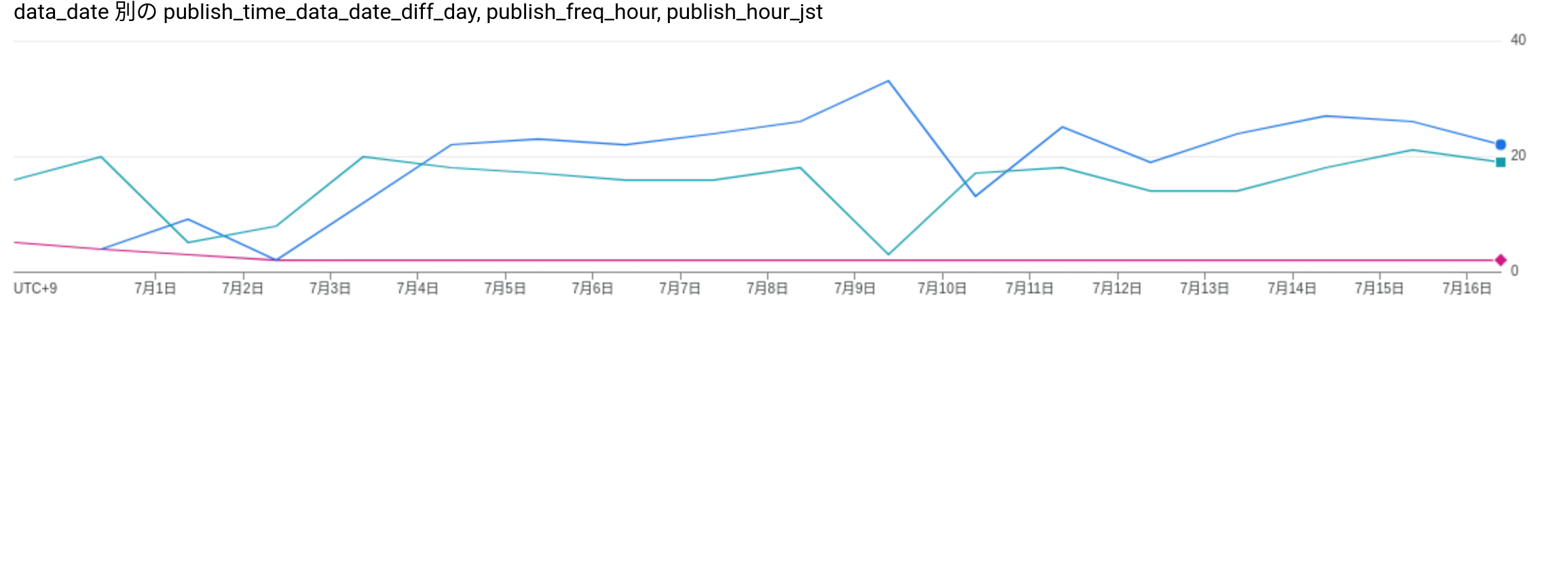
グラフの左のほうがやや不安定になっているようにみえる。これは、export設定してから1週間分のデータは遡って転送されるため、逐次転送をしているのだろう。設定したのは7/4くらいなので、確かに7/4以前は規則性がなさそう
集計
公式が一番詳しいが、クエリ実行がてらメモ
- ある一週間でのweb検索におけるURL別CTR
SELECT
url,
SAFE_DIVIDE(SUM(clicks), SUM(impressions)) AS ctr
FROM searchconsole.searchdata_url_impression
WHERE
search_type = 'WEB'
AND data_date between "2024-07-01" and DATE_ADD("2024-07-01", INTERVAL 1 WEEK)
GROUP BY 1
ORDER BY 2 DESC
---
url ctr
https://blog.uni-3.app/keras-segnet/ 0.33333333333333331
https://blog.uni-3.app/docker-swarm-openfaas/ 0.27272727272727271
https://blog.uni-3.app/julia-mandelbrot-julia-set/ 0.25
https://blog.uni-3.app/bq-ml-embedding-classification/ 0.17241379310344829
...impとclickの散布図もだしてみた。相関していそう

- 検索クエリのランキング
開発系の記事が多いからだろうが、queryはおおよそ単語でスペース区切りになっている。パースして集計してもよさそう
streamlit pdf 表示記事、適当に書いたからあれなんだけど需要あるんだよな、不思議
SELECT
query,
-- 平均掲載順位
SUM(sum_top_position)/SUM(impressions) + 1 AS rank,
SAFE_DIVIDE(SUM(clicks), SUM(impressions)) AS ctr
FROM
searchconsole.searchdata_site_impression
WHERE
query != '' -- 匿名化されたクエリを除外
AND data_date BETWEEN "2024-07-01"
AND DATE_ADD("2024-07-01", INTERVAL 1 WEEK)
GROUP BY
1
ORDER BY
2 ASC
---
query rank ctr
streamlit pdf 表示 1.0 0.8571428571428571
julia set operations 1.0 0.0
t-nse 2.0 0.0
gradio pdf viewer 2.0 1.0クエリ参考
https://support.google.com/webmasters/answer/12917174?hl=ja
これでGA4のデータも合わせればimpからクリック、閲覧まで一貫してbigquery上で集計ができそうである