SegNetは、ケンブリッジ大学が開発した画素単位でのラベリング機能を実現する、A Deep Convolutional Encoder-Decoder Architectureのこと
keras2系+tensorflowで実装してみた
とりあえず動かしたソースコードを貼っていく 解説はいずれやりたい
環境
- ubuntu: 17.04
- python: 3.6
- keras: 2.0.8
- tensorflow: 1.3.0
データの読み込み
画像のセグメンテーション用に公開しているデータを使うalexgkendall/SegNet-Tutorialリポジトリの、./CamVid内のデータを使う
クラスは12あり、順番に
[Sky, Building, Pole, Road_marking, Road, Pavement, Tree, SignSymbol, Fence, Car, Pedestrian, Bicyclist, Unlabelled]の情報がラベル付けされている
import cv2
import numpy as np
from keras.applications import imagenet_utils
import os
DataPath = './CamVid/'
data_shape = 360*480
class Dataset:
def __init__(self, classes=12, train_file='train.txt', test_file='test.txt'):
self.train_file = train_file
self.test_file = test_file
self.data_shape = 360*480
self.classes = classes
def normalized(self, rgb):
#return rgb/255.0
norm=np.zeros((rgb.shape[0], rgb.shape[1], 3),np.float32)
b=rgb[:,:,0]
g=rgb[:,:,1]
r=rgb[:,:,2]
norm[:,:,0]=cv2.equalizeHist(b)
norm[:,:,1]=cv2.equalizeHist(g)
norm[:,:,2]=cv2.equalizeHist(r)
return norm
def one_hot_it(self, labels):
x = np.zeros([360,480,12])
for i in range(360):
for j in range(480):
x[i,j,labels[i][j]] = 1
return x
def load_data(self, mode='train'):
data = []
label = []
if (mode == 'train'):
filename = self.train_file
else:
filename = self.test_file
with open(DataPath + filename) as f:
txt = f.readlines()
txt = [line.split(' ') for line in txt]
for i in range(len(txt)):
data.append(self.normalized(cv2.imread(os.getcwd() + txt[i][0][7:])))
label.append(self.one_hot_it(cv2.imread(os.getcwd() + txt[i][1][7:][:-1])[:,:,0]))
print('.',end='')
#print("train data file", os.getcwd() + txt[i][0][7:])
#print("label data raw", cv2.imread(os.getcwd() + '/CamVid/trainannot/0001TP_006690.png'))
return np.array(data), np.array(label)
def preprocess_inputs(self, X):
### @ https://github.com/fchollet/keras/blob/master/keras/applications/imagenet_utils.py
"""Preprocesses a tensor encoding a batch of images.
# Arguments
x: input Numpy tensor, 4D.
data_format: data format of the image tensor.
mode: One of "caffe", "tf".
- caffe: will convert the images from RGB to BGR,
then will zero-center each color channel with
respect to the ImageNet dataset,
without scaling.
- tf: will scale pixels between -1 and 1,
sample-wise.
# Returns
Preprocessed tensor.
"""
return imagenet_utils.preprocess_input(X)
def reshape_labels(self, y):
return np.reshape(y, (len(y), self.data_shape, self.classes))モデル
from keras.layers import Input
from keras.layers.core import Activation, Flatten, Reshape
from keras.layers.convolutional import Convolution2D, Conv2D, MaxPooling2D, UpSampling2D
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from keras.utils import np_utils
def SegNet(input_shape=(360, 480, 3), classes=12):
### @ https://github.com/alexgkendall/SegNet-Tutorial/blob/master/Example_Models/bayesian_segnet_camvid.prototxt
img_input = Input(shape=input_shape)
x = img_input
# Encoder
x = Conv2D(64, (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(128, (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(256, (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(512, (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
# Decoder
x = Conv2D(512, (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = UpSampling2D(size=(2, 2))(x)
x = Conv2D(256, (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = UpSampling2D(size=(2, 2))(x)
x = Conv2D(128, (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = UpSampling2D(size=(2, 2))(x)
x = Conv2D(64, (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Conv2D(classes, (1, 1), padding="valid")(x)
x = Reshape((input_shape[0] * input_shape[1], classes))(x)
x = Activation("softmax")(x)
model = Model(img_input, x)
return model学習
モデルデータの保存+tensorboardに学習過程を書き出す
import os
import glob
import numpy as np
import keras
from model import SegNet
import dataset
input_shape = (360, 480, 3)
classes = 12
epochs = 100
batch_size = 1
log_filepath='./logs/'
data_shape = 360*480
class_weighting = [0.2595, 0.1826, 4.5640, 0.1417, 0.5051, 0.3826, 9.6446, 1.8418, 6.6823, 6.2478, 3.0, 7.3614]
## set gpu usage
import tensorflow as tf
config = tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=True, per_process_gpu_memory_fraction = 0.8))
session = tf.Session(config=config)
keras.backend.tensorflow_backend.set_session(session)
def main():
print("loading data...")
ds = dataset.Dataset(classes=classes)
train_X, train_y = ds.load_data('train') # need to implement, y shape is (None, 360, 480, classes)
train_X = ds.preprocess_inputs(train_X)
train_Y = ds.reshape_labels(train_y)
print("input data shape...", train_X.shape)
print("input label shape...", train_Y.shape)
test_X, test_y = ds.load_data('test') # need to implement, y shape is (None, 360, 480, classes)
test_X = ds.preprocess_inputs(test_X)
test_Y = ds.reshape_labels(test_y)
tb_cb = keras.callbacks.TensorBoard(log_dir=log_filepath, histogram_freq=1, write_graph=True, write_images=True)
print("creating model...")
model = SegNet(input_shape=input_shape, classes=classes)
model.compile(loss="categorical_crossentropy", optimizer='adadelta', metrics=["accuracy"])
model.fit(train_X, train_Y, batch_size=batch_size, epochs=epochs,
verbose=1, class_weight=class_weighting , validation_data=(test_X, test_Y), shuffle=True
, callbacks=[tb_cb])
model.save('seg.h5')
if __name__ == '__main__':
main()
実行
python train.py
...
367/367 [==============================] - 139s - loss: 0.0492 - acc: 0.9806 - val_loss: 1.5358 - val_acc: 0.7349GeForce GTX 1050で行ったが、学習は100 epochで数時間かかった
学習結果
tensorboard --logdir logs
TensorBoard 0.1.5 at http://localhost:6006 (Press CTRL+C to quit)
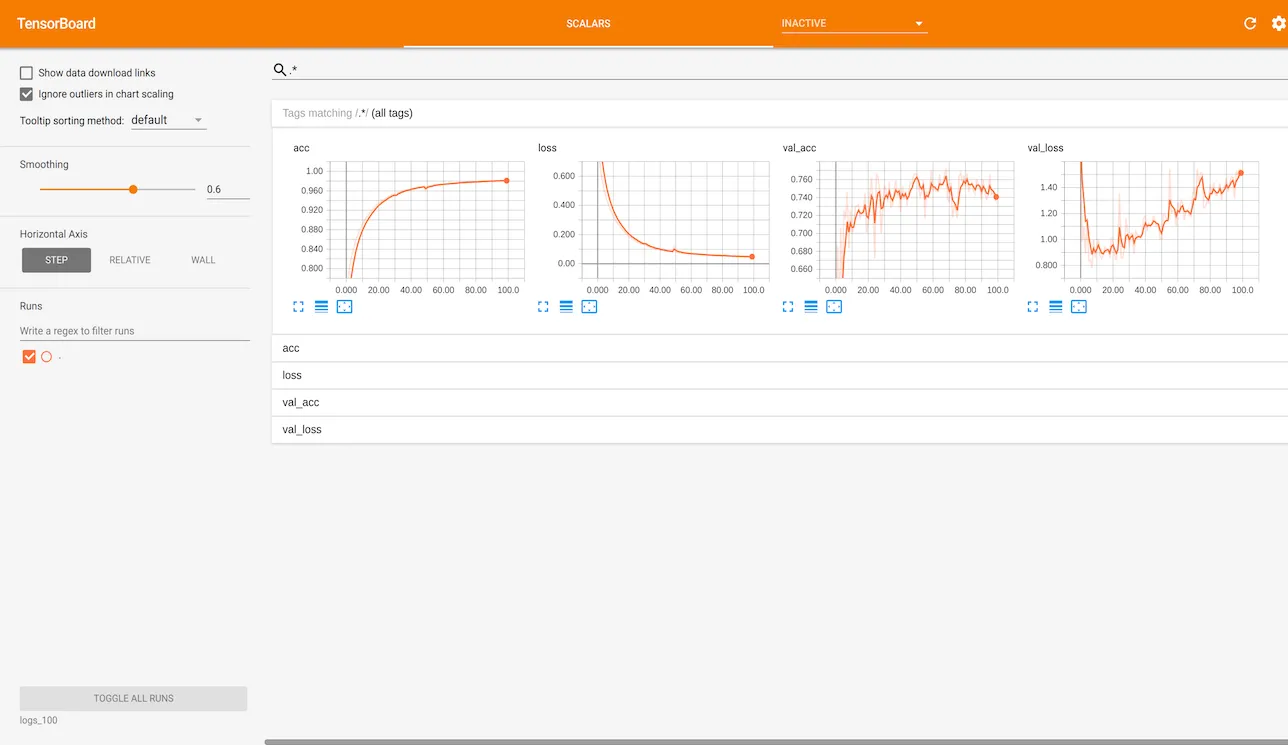
収束してなさそう?
予測結果
保存したモデルを読み込んで読み込んだ画像データを画素単位でラベリングし、セグメントされた領域を色付けして、画像を書き出す
import numpy as np
import keras
from PIL import Image
from model import SegNet
import dataset
height = 360
width = 480
classes = 12
epochs = 100
batch_size = 1
log_filepath='./logs_100/'
data_shape = 360*480
def writeImage(image, filename):
""" label data to colored image """
Sky = [128,128,128]
Building = [128,0,0]
Pole = [192,192,128]
Road_marking = [255,69,0]
Road = [128,64,128]
Pavement = [60,40,222]
Tree = [128,128,0]
SignSymbol = [192,128,128]
Fence = [64,64,128]
Car = [64,0,128]
Pedestrian = [64,64,0]
Bicyclist = [0,128,192]
Unlabelled = [0,0,0]
r = image.copy()
g = image.copy()
b = image.copy()
label_colours = np.array([Sky, Building, Pole, Road_marking, Road, Pavement, Tree, SignSymbol, Fence, Car, Pedestrian, Bicyclist, Unlabelled])
for l in range(0,12):
r[image==l] = label_colours[l,0]
g[image==l] = label_colours[l,1]
b[image==l] = label_colours[l,2]
rgb = np.zeros((image.shape[0], image.shape[1], 3))
rgb[:,:,0] = r/1.0
rgb[:,:,1] = g/1.0
rgb[:,:,2] = b/1.0
im = Image.fromarray(np.uint8(rgb))
im.save(filename)
def predict(test):
model = keras.models.load_model('seg_100.h5')
probs = model.predict(test, batch_size=1)
prob = probs[0].reshape((height, width, classes)).argmax(axis=2)
return prob
def main():
print("loading data...")
ds = dataset.Dataset(test_file='val.txt', classes=classes)
test_X, test_y = ds.load_data('test') # need to implement, y shape is (None, 360, 480, classes)
test_X = ds.preprocess_inputs(test_X)
test_Y = ds.reshape_labels(test_y)
prob = predict(test_X)
writeImage(prob, 'val.png')
if __name__ == '__main__':
main()input

output

おおむねセグメントされてる